Machine learning v jazyku R – Odhad cien bytov
Machine Learning (Strojové učenie) je podmnožina umelej inteligencie, ktorá sa zameriava na vývoj algoritmov schopných učiť sa a robiť predikcie na základe dát. V jazyku R existuje množstvo nástrojov a frameworkov, ktoré uľahčujú vytváranie a tréning ML modelov. Medzi najpopulárnejšie patrí tidymodels, ktorý poskytujú robustné a efektívne prostriedky na tvorbu rôznych modelov a predikciu. V tomto článku sa zameriam na vytvorenie modelu na predikovanie cien bytov, pričom priblížim aj tému explainable ML na lepšie porozumenie výsledkom modelu.
Úvod
V tomto blogovom príspevku prejdem procesom prípravy a tvorby ML modelu, ktorý bude na základe vložených parametrov predikovať cenu bytu. Dáta boli vopred nachystané, ich čistenie a manipuláciu si môžete pozrieť v tomto článku.
Explainable ML
V rámci strojového učenia predstavuje koncept “explainable/interpretable ML” (vysvetliteľné strojové učenie) kľúčový posun smerom k transparentnosti a interpretovateľnosti modelov. Napriek tomu, že modely ako XGBoost ponúkajú výnimočnú prediktívnu silu, ich interné rozhodovacie procesy môžu byť zložité a nejasné, a teda môžu byť tiež vnímané ako “black box”, čo znamená, že nie je ľahké pochopiť, ako sa k predikciám dospelo. Toto vnímanie komplikuje dôveru a akceptáciu modelov v kritických aplikáciách, kde je potrebné pochopenie dôvodov za predikciami.
Vysvetliteľné strojové učenie sa snaží preklenúť túto priepasť poskytujúc nástroje a metódy na objasnenie, ako modely dospeli k svojim rozhodnutiam. Knižnice ako “vip” v jazyku R a metódy ako SHAP (Shapley Additive exPlanations) hodnoty umožňujú analytikom a vývojárom lepšie pochopiť príspevky jednotlivých funkcií k výslednému predikovanému výstupu. Táto schopnosť detailne rozložiť predikčný proces umožňuje nielen hlbšiu analýzu a optimalizáciu modelov, ale tiež zvyšuje transparentnosť a dôveru zo strany koncových užívateľov.

Dôležitosť explainable/interpretable ML naberá na váhe najmä v sektoroch, kde sú dôsledky rozhodnutí založených na predikciách modelu vysoké, ako sú zdravotníctvo, financie alebo právo. V týchto oblastiach je kľúčové, aby boli modely nielen presné, ale aj ich rozhodnutia pochopiteľné a spravodlivé. Vysvetliteľné strojové učenie tak stojí v centre úsilia o vytvorenie technológií, ktoré sú nielen inteligentné, ale aj zrozumiteľné a etické.
Výborná kniha na túto tému je napríklad Interpretable Machine Learning: A Guide For Making Black Box Models Explainable, ktorá je veľmi zrorumiteľne napísaná a obsahuje aj odkazy na knižnice v R aj Pythone. Navyše je dostupná aj online. Náročnejšia publikácia je potom Explainable AI for Trees: From Local Explanations to Global Understanding, ktorá ide viac do detailu a “matematiky” na pozadí.
Načítanie knižníc a dát
Klasicky začíname s načítaním knižníc. Aj tento krát použijeme tidyverse – súbor knižníc navrhnutých na prácu s dátami v R, ktorý zahŕňa napr. ggplot2 pre vizualizáciu, dplyr pre manipuláciu s dátami, tidyr pre úpravu tvaru dát, a iné. Opäť sa objavuje knižnica sf, keďže dáta obsahujú priestorové objekty. Novikou v tomto blogu je tidymodels. Je to framework pre modelovanie a strojové učenie, ktorý poskytuje koherentnú súpravu knižníc na predspracovanie dát, rozdelenie dát, cross-validáciu, výber modelu atď. Je navrhnutý tak, aby bol v súlade s princípmi tidyverse a umožňoval ľahkú integráciu s inými nástrojmi z tohto ekosystému. Dve nasledujúce knižnice pomáhajú s konceptom “explainable/interpretable ML”. Knižnica vip je určená na vizualizáciu dôležitosti premenných v rôznych modeloch strojového učenia. Umožňuje ľahko identifikovať, ktoré premenné majú najväčší vplyv na predikcie modelu, čo je kľúčové pre interpretáciu modelu a pochopenie dát. Knižnica shapviz je špecificky navrhnutá na výpočet a vizualizáciu SHAP hodnôt pre modely vytvorené pomocou XGBoost v R. SHAP hodnoty poskytujú podrobné vysvetlenie predikcií modelu na úrovni jednotlivých pozorovaní, čo pomáha v interpretácii “black box” modelov. Umožnujú pochopiť, ako dôležité sú premenné v rámci modelu. doParallel slúži na paralelné výpočty, a teda skrátenie času trénovania modelu. Posledná knižnica extrafont slúži na načítanie fontov inštalovaných na Windows-e.
Knižnice
# import libraries
if (!require("pacman")) {
install.packages("pacman")
}
pacman::p_load(
tidyverse,
sf, # data contain geometry
tidymodels,
vip,
shapviz,
doParallel,
extrafont,
vetiver,
xgboost
)
loadfonts(device = "win")
options(scipen = 999)
unregister_dopar <- function() {
env <- foreach:::.foreachGlobals
rm(list = ls(name = env), pos = env)
}Dáta
# import data
original_conditions <- c(
"Pôvodný stav", "Čiastočná rekonštrukcia", "Kompletná rekonštrukcia",
"Novostavba", "Vo výstavbe", "Developerský projekt"
)
english_conditions <- c(
"Original condition", "Partial reconstruction", "Complete reconstruction",
"New building", "Under construction", "Development project"
)
original_type <- c("3 izbový byt", "1 izbový byt", "2 izbový byt", "4 izbový byt", "Garsónka", "5 a viac izbový byt", "Dvojgarsónka")
english_type <- c("3-room apartment", "1-room apartment", "2-room apartment", "4-room apartment", "Studio", "5 or more room apartment", "Two-room apartment")
apartments_analysis_data <- readRDS("data/apartments_final_data.rds") |>
filter(!is.na(price)) |>
mutate(
coord = st_coordinates(st_centroid(geometry)),
lon = coord[, 1],
lat = coord[, 2],
type = str_replace_na(recode(type, !!!setNames(original_type, english_type)),"Neznáme"),
condition = str_replace_na(recode(condition, !!!setNames(original_conditions, english_conditions)),"Neznáme"),
certificate = str_replace_na(str_replace(certificate, "none", "Nemá"), "Neznáme")
) |>
select(-coord) # Optionally remove the original coordinates column
# remove geometry since we have coordinates now
apartments_analysis_data$geometry <- NULL
saveRDS(apartments_analysis_data, "data/apartments_data_App.RDS")Tidymodels framework
Tidymodels je súbor knižníc v R, ktorý poskytuje jednotné a flexibilné rozhranie pre celý proces strojového učenia, od predspracovania dát cez ich analýzu až po modelovanie. Vytvorenie modelu v rámci frameworku tidymodels pozostáva z niekoľkých základných krokov:
- Príprava a rozdelenie dát: Prvý krok je rozdelenie nášho “dátového budgetu”. Typicky sa dáta delia na trénovaciu (slúži na odhad parametrov modelu) a testovaciu (slúži na nezávislé zhodnotenie modelu) sadu pomocou funkcie initial_split(). Tento krok je základom pre overovanie modelu a zabránenie overfittingu. S využitím vfold_cv() alebo podobných funkcií vytvoríme schému krížovej validácie (rôzne verzie tréningových dát – tzv. “folds”), ktorá sa použije na evaluáciu modelu.
Ako rozdelenie na tréningovú a testovaciu sadu, tak aj vytvorenie validačných schém umožnuje specifikovať premennú, ktorej rozdelenie ostane (približne) zachované (strata =).

Vytvorenie receptu (recipe): recipe() definuje predspracovanie dát, vrátane výberu premenných, transformácií, normalizácie, kódovania kategorických premenných a riešenia chýbajúcich hodnôt. Jednotlivé kroky sa pridávajú pomocou step_*() funkcií. Recipies zabezpečujú, že predspracovanie je konzistentné a reprodukovateľné.
Špecifikácia modelu: Model sa špecifikuje nezávisle od dát. Pomocou funkcií ako linear_reg(), rand_forest(), boost_tree() a iných definujeme typ modelu, mód (regresia, klasifikácia), engine(xgboost, lightgbm…) a jeho hlavné parametre bez toho, aby sme ich ihneď fitovali na dáta. Tento krok umožňuje flexibilitu v experimentovaní s rôznymi modelmi.
Nastavenie workflow: workflow() integruje recept a model do jednotného objektu. Workflow umožňuje efektívnejšie spracovanie, keďže spojíme predspracovanie dát a modelovanie do jednej operácie, čo zjednodušuje evaluáciu a porovnávanie modelov.
Výber a nastavenie hyperparametrov: Pomocou parameters() môžeme definovať a prispôsobiť rozsahy hyperparametrov pre tuning modelu. Tidymodels ponúka rôzne metódy pre vyhľadávanie optimálnych hodnôt, napr. tune_grid(), tune_bayes(), tune_race() a iné.
Cross-validácia a tuning modelu: Tuning hyperparametrov prebieha na trénovacej sade (resp. na jednotlivých “fold-och”) s cieľom nájsť najlepšiu kombináciu hyperparametrov. Najlepší model vyberieme pomocou funkcie select_best(), pričom špecifikujeme metriku, podľa ktorej model vyberáme.
Finalizácia a fitovanie modelu: Po vybraní najlepších hyperparametrov finalizujeme model pomocou finalize_model() a potom ho fitujete na trénovacie dáta s fit(). Tento krok produkuje finálny model pripravený na evaluáciu a predikcie.
Evaluácia modelu: Pomocou testovacej sady dát overíme výkonnosť modelu. Metriky ako RMSE, presnosť (accuracy), AUC a mnoho iných (výber by mal zodpovedať nášmu cieľu, čo platí najmä pri klasifikácii) poskytujú hodnotenie, ako dobre model predpovedá nevidené dáta.
Tieto kroky poskytujú ucelený prístup k vytváraniu, optimalizácii a evaluácii prediktívnych modelov. Tidymodels zabezpečuje konzistenciu a reprodukovateľnosť po celom procese.
Toto je opis základného procesu tvorby ML modelu pomocou tidymodels frameworku. Je možné samozrejme vytvoriť aj omnoho komplikovanejší proces s postupným tuningom hyperparametrov, tvorbou stacked modelu (meta-learner modelu) atď.
Tvorba modelu
Rozdelenie dát
# split dataframes to train(80)/test(20)
set.seed(123)
apartments_train_split <- initial_split(apartments_analysis_data, prop = 0.7, strata = price)
apartments_train <- training(apartments_train_split)
apartments_test <- testing(apartments_train_split)
folds <- vfold_cv(apartments_train, v = 5, strata = price)
saveRDS(apartments_test, "data/test_set.RDS")Spracovanie dát
apartments_xgboost_recipe <- recipe(apartments_train, price ~ .) |>
step_rm(name_nsi) |>
step_string2factor(all_nominal_predictors()) |>
step_impute_knn(all_nominal_predictors()) |>
step_unknown(all_nominal_predictors()) |>
step_dummy(all_nominal_predictors())Špeficikácia modelu
xgb_model <-
boost_tree(
trees = tune(), loss_reduction = tune(),
tree_depth = tune(), min_n = tune(),
mtry = tune(), sample_size = tune(),
learn_rate = tune()
) |>
set_mode("regression") |>
set_engine("xgboost")Workflow
apartments_workflow <- workflow() |>
add_recipe(apartments_xgboost_recipe) |>
add_model(xgb_model)Výber parametrov
apartments_xgboost_params <- parameters(
trees(), learn_rate(), loss_reduction(),
tree_depth(), min_n(),
sample_size = sample_prop(),
finalize(mtry(), apartments_train)
)
apartments_xgboost_params <- apartments_xgboost_params |> update(trees = trees(c(300, 600)))
Pri tuningu použijeme paralelné spracovanie na x – 2 jadrách. Niektoré algoritmy umožnujú aj spracovanie pomocou GPU ak je dostupná kompatibilná grafická karta (bavíme sa o tvorbe modelu na lokálnom zariadení, samozrejme v produkcii je vhodnejšie využiť služby ako GCP, AWS a iné)
Tuning parametrov
registerDoParallel(cores = detectCores() - 1)
xgboost_tune <-
apartments_workflow |>
tune_bayes(
resamples = folds,
param_info = apartments_xgboost_params,
iter = 100,
metrics = metric_set(rmse, mape),
control = control_bayes(
no_improve = 20,
save_pred = T, verbose = F
)
)
unregister_dopar()Finalizácia modelu
apartments_best_model <- select_best(xgboost_tune, metric = "rmse")
apartments_final_model <- finalize_model(xgb_model, apartments_best_model)
apartments_workflow <- apartments_workflow |> update_model(apartments_final_model)
apartments_xgb_fit <- fit(apartments_workflow, data = apartments_train)
saveRDS(apartments_xgb_fit, "data/xgb_fit.RDS")Výsledné metriky a testovacia predikcia
apartments_final_res <- last_fit(apartments_workflow, split = apartments_train_split)
apartments_pred <-
predict(apartments_xgb_fit, apartments_test) |>
bind_cols(apartments_test)Vyhodnotenie modelu
Z grafu je zrejmé, že výsledný model vcelku dobre predikuje ceny bytov s hodnotou do približne 300 tisíc EUR. Pri drahších bytoch je variabilita odchýlok od reálnych cien vyššia.
Porovnanie predikcie s reálnou cenou 1
plot1 <-
apartments_pred |>
ggplot(aes(x = .pred, y = price)) +
geom_point() +
geom_smooth(method = "loess", color = "red") +
scale_y_continuous(labels = function(x) format(x, big.mark = " ", scientific = FALSE), breaks = c(200000, 400000, 600000)) +
scale_x_continuous(labels = function(x) format(x, big.mark = " ", scientific = FALSE), breaks = c(200000, 400000, 600000)) +
labs(
title = NULL,
x = "Predikovaná cena",
y = "Reálna Cena"
) +
theme_minimal() +
theme(
text = element_text(family = "Courier New", size = 12)
) +
coord_fixed()
plot1
Pri pohľade na rozloženie reálnych a predikovaných cien môžeme vidieť kde presne dochádza k najväčším odchýlkam. Model predikoval viac bytov v cene približne 100 až 170 tisíc EUR a približne 200 až 225 tisíc EUR. Naopak menej zastúpené sú najmä byty s cenou približne 250 až 300 tisíc EUR. Teraz je potrebné rozhodnutie, či sa treba vrátiť k procesu feature engineering, čiže manipulácii s premennými alebo pokračovať s model v stave v akom je.
Porovnanie predikcie s reálnou cenou 2
plot2 <-
apartments_pred |>
select(predikcia = .pred, realita = price) |>
gather(key, value) |>
ggplot(aes(x = value, color = key)) +
geom_density(alpha = .5) +
labs(
title = NULL,
x = "Cena",
y = "Hustota",
color = ""
) +
scale_y_continuous(labels = function(x) format(x, big.mark = " ", scientific = FALSE)) +
scale_x_continuous(labels = function(x) format(x, big.mark = " ", scientific = FALSE)) +
theme_minimal() +
theme(
text = element_text(family = "Courier New", size = 12),
legend.position = "bottom"
)
plot2
Model v priemere mierne nadhodnocuje (do 5 percent) byty s reálnou cenou medzi 100 až 170 tisíc EUR. Najvyššie nadhodnotenie (viac ako 5 percent) je pri cenách do 100 tisíc EUR. Naopak byty s cenou od 180 tisíc EUR do 260 tisíc eur mierne podhodnocuje. V prípade bytov od 260 tisíc EUR (približne 7 percent z inzerátov) sú už odchýlky nestabilné, trend je však smerom k výraznejšiemu podhodnocovaniu.
Odchýlky
# Calculate the difference between prediction and actual value
plot3_data <- apartments_pred |>
select(.pred, price) |>
mutate(diff = .pred - price,
bin = floor(price/10000)*10000) |>
group_by(bin) |>
summarize(mean_diff = mean(diff)) |>
mutate(rel_diff = case_when(
mean_diff/bin >= 0.05 ~ 0.05,
mean_diff/bin >= 0 ~ 0,
mean_diff/bin <= -0.05 ~ -0.05,
mean_diff/bin < 0 ~ -0.02
))
# Plot with coloring based on mean difference
plot3 <- ggplot(plot3_data, aes(x = bin, y = mean_diff, color = factor(rel_diff))) +
geom_point() +
labs(
title = NULL,
x = "Cena",
y = "Priemerná chyba"
) +
scale_color_manual(values = c("#506BA0", "#55B9F5", "#90ee90","#037f51" )) +
scale_y_continuous(labels = function(x) format(x, big.mark = " ", scientific = FALSE)) +
scale_x_continuous(labels = function(x) format(x, big.mark = " ", scientific = FALSE)) +
theme_minimal() +
theme(
text = element_text(family = "Courier New", size = 12),
legend.position = "none")
plot3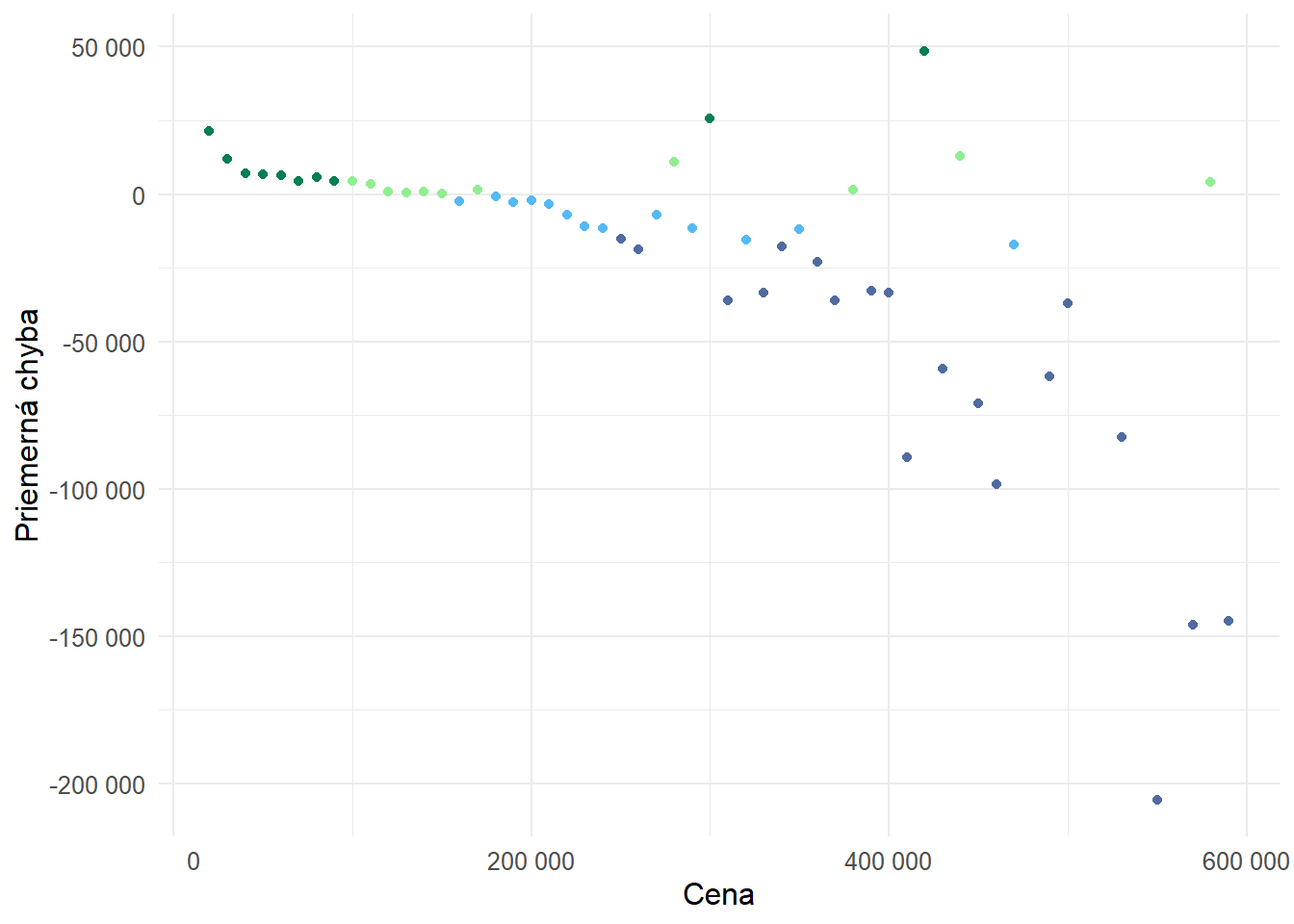
Pri XGBoost je dôležitosť premenných založená na Gain, tento termín odkazuje na príspevok každej premennej k celkovému zlepšeniu modelu, ktoré je dosiahnuté vďaka rozdeleniam (splits) na konkrétnej premennej. Keď XGBoost vytvára stromy, každé rozdelenie v strome sa vyberá tak, aby maximalizovalo “zisk”, čo znamená, že sa snaží o čo najväčšie zlepšenie prediktívnej presnosti. Gain v tomto kontexte meria, o koľko sa zlepšuje predikcia, keď sa použije rozdelenie založené na danej premennej. Tento zisk je často vážený a sumarizovaný cez všetky stromy v modeli. Premenné, ktoré najviac prispievajú k zlepšeniu sú tie, ktoré model najviac využíva na dosiahnutie presnejších predikcií, a preto sú považované za dôležitejšie. Viac informácií môžete nájsť napríklad v tomto článku na medium.com.
Najdôležitejšou premennou je podľa modelu geografická dĺžka. Nasledujú rozloha bytu a lokalita Bratislava I. Až 4 z top 10 premenných súvisia s indexom bývania.
vip – Variable Importance Plots
apartments_xgb_fit |>
fit(data = apartments_train) |>
pull_workflow_fit() |>
vip(geom = "point", include_type = TRUE) +
theme_minimal() +
theme(
panel.grid.minor = element_blank(),
text = element_text(family = "Courier New", size = 12)
) +
labs(
y = "Dôležitosť",
x = "Premenná"
) +
theme(
panel.grid.minor = element_blank(),
text = element_text(family = "Courier New", size = 12)
)
SHAP (Shapley Additive exPlanations) hodnoty sú metóda používaná na vysvetlenie príspevku jednotlivých premenných k predikcii konkrétneho modelu strojového učenia. SHAP hodnoty poskytujú detailné vysvetlenie predikcie pre každý záznam (riadok dát) tým, že ukážu, ako každá premenná prispieva k výslednej predikcii, či už zvyšovaním alebo znížením predikovanej hodnoty. Tiež zaručujú konzistentnosť, čo znamená, že ak máme dve premenné a jedna konzistentne prispieva k predikcii viac než druhá, bude mať aj vyššiu SHAP hodnotu. Okrem poskytovania vysvetlení na úrovni jednotlivých predikcií (lokálne vysvetlenie) môžu byť SHAP hodnoty agregované na poskytnutie prehľadu o dôležitosti premenných v celom modeli (globálne vysvetlenie).
SHAP hodnoty nám poskytujú ďaľšie informácie k dôležitosti premenných. Napr. sa potvrdzuje západo-východný gradient, ktorý sme spomínali v závere tretej časti tejto série. Ak sa byt nachádza v okrese Bratislava I, môže mu to pridať na hodnote 45 až 95 tisíc EUR. Ak sa jedná o novostavbu cena môže stúpnuť o 15 až 50 tisíc EUR, kompletná rekonštrukcia pridáva na hodnote do 25 tisíc EUR, naopak pôvodný stav má negatívny efekt do približne -20 tisíc EUR.
SHAP
fitted_data <- apartments_xgboost_recipe |>
prep() |>
bake(new_data = apartments_analysis_data) |>
select(-price)
set.seed(123)
shp <- shapviz(extract_fit_engine(apartments_xgb_fit), X_pred = fitted_data |> as.matrix())
shap_plot <- sv_importance(shp, kind = "beeswarm") +
scale_x_continuous(labels = function(x) format(x, big.mark = " ", scientific = FALSE)) +
scale_color_gradient(low = "blue", high = "red",
breaks = c(0,1),
labels = c("nízka", "vysoká"),
guide = guide_colorbar(barwidth = 12, barheight = 0.3)) + # Customize based on your exact needs
labs(x = "SHAP hodnota (vplyv na predikovanú cenu)",
y = "Premenná",
color = "Hodnota premennej "
) +
theme_minimal() +
theme(
panel.grid.minor = element_blank(),
text = element_text(family = "Courier New", size = 10),
legend.position = "bottom"
)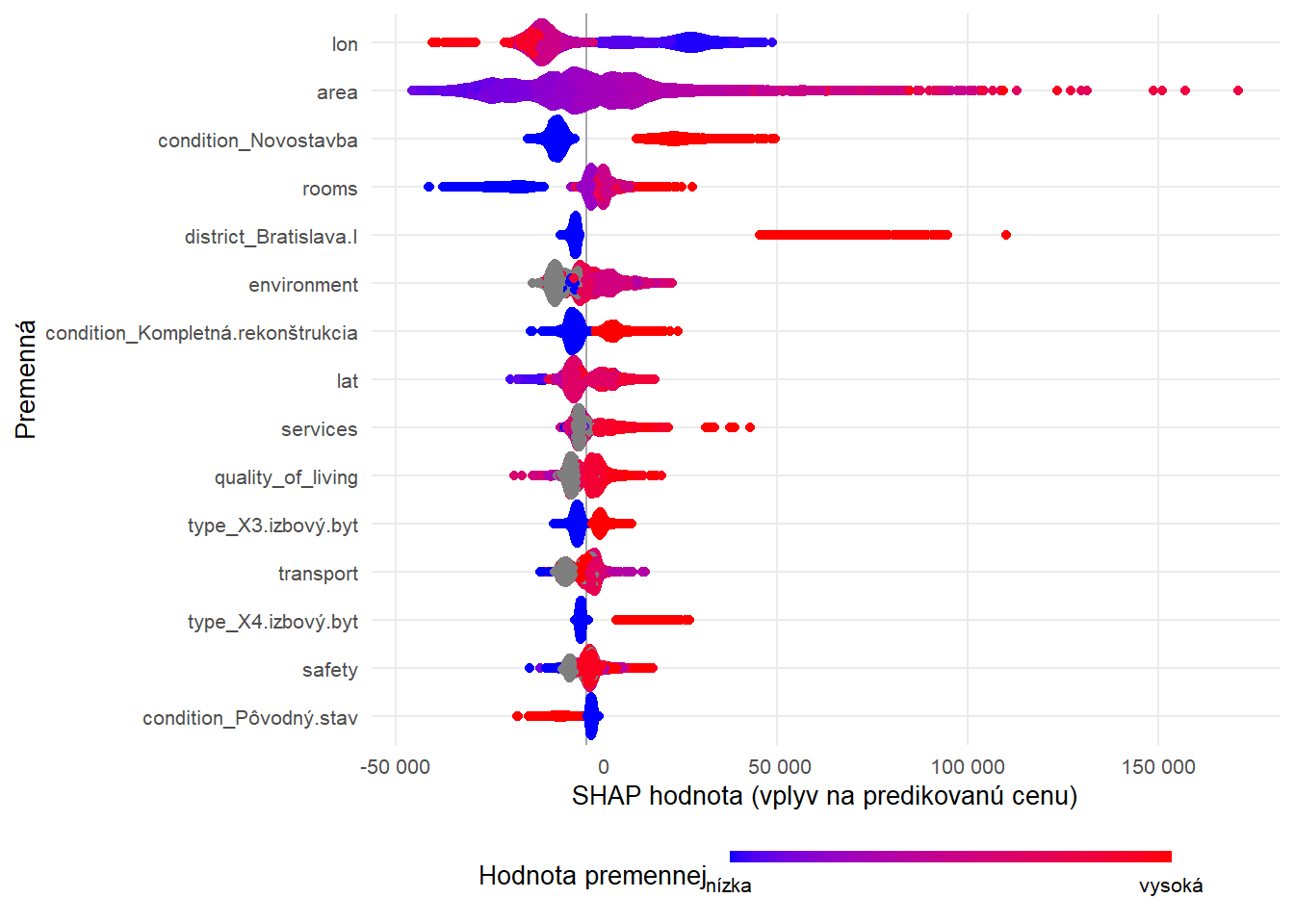
Okrem celkového príspevku jednotlivých premenných v rámci modelu ako celku (globálne vysvetlenie) sa vieme pozrieť aj na jednotlivé predikcie. Napr. keď sa pozrieme na inzerát na riadku 1804, môžeme vidieť, že lokalita v okrese Bratislava I mu pridala na hodnote 63 tisíc EUR, geografická dĺžka ďalších 33 tisíc EUR a rozloha 84 m2 20 tisíc EUR. Naopak to, že sa nejedná o novostavbu znižuje cenu o 12 tisíc EUR a pôvodný stav uberá ďalších 9 tisíc EUR.

Uloženie modelu a dát pre aplikáciu
Aby sa model dal použiť v Shiny aplikácii, je nutné ho uložiť vo vhodnom formáte. Natrénovaný model transformujeme na vetiver model. Tento objekt obsahuje všetko, čo treba, aby sa dal použiť v novom prostredí. Ďalej ukladáme engine pomocou knižnice xgboost. Budeme ho potrebovať pri SHAP grafe.
You might also like
-
Ako vytvoriť API v R pomocou knižnice Plumber https://cleandata.sk/wp-content/themes/engic/images/empty/thumbnail.jpg 150 150 cleandata https://secure.gravatar.com/avatar/ee96a699da7fa28e99fc6752011335df?s=96&d=mm&r=g

-
Ako zrýchliť XGBoost v R: Benchmark trénovania modelu na CPU vs. GPU https://cleandata.sk/wp-content/themes/engic/images/empty/thumbnail.jpg 150 150 cleandata https://secure.gravatar.com/avatar/ee96a699da7fa28e99fc6752011335df?s=96&d=mm&r=g
-
EDA časových radov: Ako odhaliť vzory skryté v čase https://cleandata.sk/wp-content/themes/engic/images/empty/thumbnail.jpg 150 150 cleandata https://secure.gravatar.com/avatar/ee96a699da7fa28e99fc6752011335df?s=96&d=mm&r=g

Leave a Reply