EDA časových radov: Ako odhaliť vzory skryté v čase
V tomto blogu sa pozriem na EDA časových radov – kľúčový prvý krok pri práci s týmito dátami. Preskúmam rôzne metódy, ako dekompozícia, vizualizácia, lagované hodnoty, diferenciácia a detekcia anomálií, ktoré pomáhajú odhaliť vzory skryté v čase.
Úvod
Tento dokument slúži ako sprievodca pre exploratívnu analýzu dát (EDA) a analýzu časových radov (TS – time series) s použitím ekosystému tidyverts v R. Cieľom je predstaviť kroky potrebné na prípravu, transformáciu a analýzu časových radov s dôrazom na vizualizácie, dekompozíciu a detekciu anomálií. Všetky príklady využívajú syntetické dáta zahŕňajúce mesačné predaje od roku 2016 do septembra 2024.
Načítanie knižníc a dát
Kód
library(tsibble)
library(fable)
library(fabletools)
library(feasts)
library(readr) # data load
library(openxlsx) # data load
library(skimr) # EDA
library(ggplot2) # visualization
library(lubridate) # time functions
library(dplyr) # data manipulation
library(tidyr) # fill
library(plotly) # interactive visualization
library(cluster) # kmeans clustering of TS
library(priceR) # exchange rates
library(janitor) # clean_names()
library(anomalize) # anomaly detection
#library(tsfeatures)
library(patchwork) # plots alignment
options(scipen = 100)
options(digits = 5)
theme_custom <- theme(
text = element_text(size = 12),
panel.grid = element_blank(),
panel.grid.major.y = element_line(colour = "#e3e1e1",
linetype = 2),
panel.border = element_blank(),
panel.background = element_blank(),
plot.title.position = 'plot',
legend.position = 'top',
legend.title = element_blank()
)
theme_set(theme_minimal() + theme_custom)
set.seed(1)
# sales data
data <- read_rds("data/dummy_data_adj.RDS") |> select(-daily_sales)
cur_PLN <- read_rds("data/cur_PLN.RDS")
cur_CZK <- read_rds("data/cur_CZK.RDS")
# all dates
all_dates <- data %>%
select(date) %>%
distinct()
# CPI euro zone
CPI_eur <- read_csv("data/CPI euro zone.csv") |>
clean_names() |>
mutate(date = ceiling_date(date, "month") - 1)
colnames(CPI_eur) <- c('date','CPI_euro')
# CPI Poland
CPI_poland <- all_dates |>
left_join(read_csv("data/CPI poland.csv") |>
clean_names(),
by = join_by(date),
keep = FALSE) |>
mutate(date = ceiling_date(date, "month") - 1) |>
arrange(date) |>
fill(2, .direction = "down")
colnames(CPI_poland) <- c('date','CPI_poland')
# CPI Czech Republic
CPI_czech_rep <- read_csv("data/CPI czech rep.csv") |>
clean_names() |>
mutate(date = ceiling_date(date, "month") - 1)
colnames(CPI_czech_rep) <- c('date','CPI_czech')Prehľad dát
Dataset obsahuje:
- Dátum: Mesačné údaje od roku 2016 po september 2024 (105 mesiacov).
- Kategorické premenné: Krajina (3 krajiny), Divízia (2 divízie), Kanál (3 kanály), Produktová skupina (6 skupín).
- Číselné premenné: Predaje a upravené predaje.
Na rýchle zhrnutie dát použijeme knižnicu skimr:
Kód
skim(data)| Name | data |
| Number of rows | 5670 |
| Number of columns | 6 |
| _______________________ | |
| Column type frequency: | |
| Date | 1 |
| character | 4 |
| numeric | 1 |
| ________________________ | |
| Group variables | None |
Variable type: Date
| skim_variable | n_missing | complete_rate | min | max | median | n_unique |
|---|---|---|---|---|---|---|
| date | 0 | 1 | 2016-01-01 | 2024-09-01 | 2020-05-01 | 105 |
Variable type: character
| skim_variable | n_missing | complete_rate | min | max | empty | n_unique | whitespace |
|---|---|---|---|---|---|---|---|
| country | 0 | 1 | 2 | 2 | 0 | 3 | 0 |
| division | 0 | 1 | 6 | 9 | 0 | 2 | 0 |
| channel | 0 | 1 | 3 | 6 | 0 | 3 | 0 |
| product_group | 0 | 1 | 3 | 11 | 0 | 6 | 0 |
Variable type: numeric
| skim_variable | n_missing | complete_rate | mean | sd | p0 | p25 | p50 | p75 | p100 | hist |
|---|---|---|---|---|---|---|---|---|---|---|
| sales | 0 | 1 | 433618 | 835656 | 142.8 | 23204 | 68880 | 431096 | 8016713 | ▇▁▁▁▁ |
Overenie pravidelnosti a úplnosti dát
Kód
# Pravidelnosť podľa krajiny
data |> group_by(country) |> skim()| Name | group_by(data, country) |
| Number of rows | 5670 |
| Number of columns | 6 |
| _______________________ | |
| Column type frequency: | |
| Date | 1 |
| character | 3 |
| numeric | 1 |
| ________________________ | |
| Group variables | country |
Variable type: Date
| skim_variable | country | n_missing | complete_rate | min | max | median | n_unique |
|---|---|---|---|---|---|---|---|
| date | CZ | 0 | 1 | 2016-01-01 | 2024-09-01 | 2020-05-01 | 105 |
| date | PL | 0 | 1 | 2016-01-01 | 2024-09-01 | 2020-05-01 | 105 |
| date | SK | 0 | 1 | 2016-01-01 | 2024-09-01 | 2020-05-01 | 105 |
Variable type: character
| skim_variable | country | n_missing | complete_rate | min | max | empty | n_unique | whitespace |
|---|---|---|---|---|---|---|---|---|
| division | CZ | 0 | 1 | 6 | 9 | 0 | 2 | 0 |
| division | PL | 0 | 1 | 6 | 9 | 0 | 2 | 0 |
| division | SK | 0 | 1 | 6 | 9 | 0 | 2 | 0 |
| channel | CZ | 0 | 1 | 3 | 6 | 0 | 3 | 0 |
| channel | PL | 0 | 1 | 3 | 6 | 0 | 3 | 0 |
| channel | SK | 0 | 1 | 3 | 6 | 0 | 3 | 0 |
| product_group | CZ | 0 | 1 | 3 | 11 | 0 | 6 | 0 |
| product_group | PL | 0 | 1 | 3 | 11 | 0 | 6 | 0 |
| product_group | SK | 0 | 1 | 3 | 11 | 0 | 6 | 0 |
Variable type: numeric
| skim_variable | country | n_missing | complete_rate | mean | sd | p0 | p25 | p50 | p75 | p100 | hist |
|---|---|---|---|---|---|---|---|---|---|---|---|
| sales | CZ | 0 | 1 | 1183321 | 1114885 | 17362.00 | 421734.5 | 883945 | 1587691 | 8016713 | ▇▂▁▁▁ |
| sales | PL | 0 | 1 | 87224 | 82084 | 223.55 | 25601.0 | 61161 | 115520 | 506350 | ▇▂▁▁▁ |
| sales | SK | 0 | 1 | 30309 | 29075 | 142.80 | 9778.5 | 22315 | 40390 | 195893 | ▇▂▁▁▁ |
Kód
# Úplnosť na najdetailnejšej úrovni
data |> group_by(country, product_group) |> skim()| Name | group_by(data, country, p… |
| Number of rows | 5670 |
| Number of columns | 6 |
| _______________________ | |
| Column type frequency: | |
| Date | 1 |
| character | 2 |
| numeric | 1 |
| ________________________ | |
| Group variables | country, product_group |
Variable type: Date
| skim_variable | country | product_group | n_missing | complete_rate | min | max | median | n_unique |
|---|---|---|---|---|---|---|---|---|
| date | CZ | Accessories | 0 | 1 | 2016-01-01 | 2024-09-01 | 2020-05-01 | 105 |
| date | CZ | Components | 0 | 1 | 2016-01-01 | 2024-09-01 | 2020-05-01 | 105 |
| date | CZ | Monitors | 0 | 1 | 2016-01-01 | 2024-09-01 | 2020-05-01 | 105 |
| date | CZ | Notebooks | 0 | 1 | 2016-01-01 | 2024-09-01 | 2020-05-01 | 105 |
| date | CZ | PCs | 0 | 1 | 2016-01-01 | 2024-09-01 | 2020-05-01 | 105 |
| date | CZ | Software | 0 | 1 | 2016-01-01 | 2024-09-01 | 2020-05-01 | 105 |
| date | PL | Accessories | 0 | 1 | 2016-01-01 | 2024-09-01 | 2020-05-01 | 105 |
| date | PL | Components | 0 | 1 | 2016-01-01 | 2024-09-01 | 2020-05-01 | 105 |
| date | PL | Monitors | 0 | 1 | 2016-01-01 | 2024-09-01 | 2020-05-01 | 105 |
| date | PL | Notebooks | 0 | 1 | 2016-01-01 | 2024-09-01 | 2020-05-01 | 105 |
| date | PL | PCs | 0 | 1 | 2016-01-01 | 2024-09-01 | 2020-05-01 | 105 |
| date | PL | Software | 0 | 1 | 2016-01-01 | 2024-09-01 | 2020-05-01 | 105 |
| date | SK | Accessories | 0 | 1 | 2016-01-01 | 2024-09-01 | 2020-05-01 | 105 |
| date | SK | Components | 0 | 1 | 2016-01-01 | 2024-09-01 | 2020-05-01 | 105 |
| date | SK | Monitors | 0 | 1 | 2016-01-01 | 2024-09-01 | 2020-05-01 | 105 |
| date | SK | Notebooks | 0 | 1 | 2016-01-01 | 2024-09-01 | 2020-05-01 | 105 |
| date | SK | PCs | 0 | 1 | 2016-01-01 | 2024-09-01 | 2020-05-01 | 105 |
| date | SK | Software | 0 | 1 | 2016-01-01 | 2024-09-01 | 2020-05-01 | 105 |
Variable type: character
| skim_variable | country | product_group | n_missing | complete_rate | min | max | empty | n_unique | whitespace |
|---|---|---|---|---|---|---|---|---|---|
| division | CZ | Accessories | 0 | 1 | 6 | 9 | 0 | 2 | 0 |
| division | CZ | Components | 0 | 1 | 6 | 9 | 0 | 2 | 0 |
| division | CZ | Monitors | 0 | 1 | 6 | 9 | 0 | 2 | 0 |
| division | CZ | Notebooks | 0 | 1 | 6 | 9 | 0 | 2 | 0 |
| division | CZ | PCs | 0 | 1 | 6 | 9 | 0 | 2 | 0 |
| division | CZ | Software | 0 | 1 | 6 | 9 | 0 | 2 | 0 |
| division | PL | Accessories | 0 | 1 | 6 | 9 | 0 | 2 | 0 |
| division | PL | Components | 0 | 1 | 6 | 9 | 0 | 2 | 0 |
| division | PL | Monitors | 0 | 1 | 6 | 9 | 0 | 2 | 0 |
| division | PL | Notebooks | 0 | 1 | 6 | 9 | 0 | 2 | 0 |
| division | PL | PCs | 0 | 1 | 6 | 9 | 0 | 2 | 0 |
| division | PL | Software | 0 | 1 | 6 | 9 | 0 | 2 | 0 |
| division | SK | Accessories | 0 | 1 | 6 | 9 | 0 | 2 | 0 |
| division | SK | Components | 0 | 1 | 6 | 9 | 0 | 2 | 0 |
| division | SK | Monitors | 0 | 1 | 6 | 9 | 0 | 2 | 0 |
| division | SK | Notebooks | 0 | 1 | 6 | 9 | 0 | 2 | 0 |
| division | SK | PCs | 0 | 1 | 6 | 9 | 0 | 2 | 0 |
| division | SK | Software | 0 | 1 | 6 | 9 | 0 | 2 | 0 |
| channel | CZ | Accessories | 0 | 1 | 3 | 6 | 0 | 3 | 0 |
| channel | CZ | Components | 0 | 1 | 3 | 6 | 0 | 3 | 0 |
| channel | CZ | Monitors | 0 | 1 | 3 | 6 | 0 | 3 | 0 |
| channel | CZ | Notebooks | 0 | 1 | 3 | 6 | 0 | 3 | 0 |
| channel | CZ | PCs | 0 | 1 | 3 | 6 | 0 | 3 | 0 |
| channel | CZ | Software | 0 | 1 | 3 | 6 | 0 | 3 | 0 |
| channel | PL | Accessories | 0 | 1 | 3 | 6 | 0 | 3 | 0 |
| channel | PL | Components | 0 | 1 | 3 | 6 | 0 | 3 | 0 |
| channel | PL | Monitors | 0 | 1 | 3 | 6 | 0 | 3 | 0 |
| channel | PL | Notebooks | 0 | 1 | 3 | 6 | 0 | 3 | 0 |
| channel | PL | PCs | 0 | 1 | 3 | 6 | 0 | 3 | 0 |
| channel | PL | Software | 0 | 1 | 3 | 6 | 0 | 3 | 0 |
| channel | SK | Accessories | 0 | 1 | 3 | 6 | 0 | 3 | 0 |
| channel | SK | Components | 0 | 1 | 3 | 6 | 0 | 3 | 0 |
| channel | SK | Monitors | 0 | 1 | 3 | 6 | 0 | 3 | 0 |
| channel | SK | Notebooks | 0 | 1 | 3 | 6 | 0 | 3 | 0 |
| channel | SK | PCs | 0 | 1 | 3 | 6 | 0 | 3 | 0 |
| channel | SK | Software | 0 | 1 | 3 | 6 | 0 | 3 | 0 |
Variable type: numeric
| skim_variable | country | product_group | n_missing | complete_rate | mean | sd | p0 | p25 | p50 | p75 | p100 | hist |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| sales | CZ | Accessories | 0 | 1 | 666039 | 425783.5 | 76791.00 | 151481.8 | 753222 | 974967 | 1600736 | ▇▂▇▅▂ |
| sales | CZ | Components | 0 | 1 | 611579 | 556714.7 | 17362.00 | 62311.0 | 475303 | 1132971 | 1911453 | ▇▂▃▃▁ |
| sales | CZ | Monitors | 0 | 1 | 1164950 | 909263.7 | 106864.00 | 225066.2 | 1100832 | 1804482 | 3620145 | ▇▅▃▂▁ |
| sales | CZ | Notebooks | 0 | 1 | 2001212 | 1705874.3 | 194954.00 | 534365.7 | 1629913 | 2857594 | 8016713 | ▇▅▁▁▁ |
| sales | CZ | PCs | 0 | 1 | 1923540 | 1047222.3 | 446793.00 | 834311.5 | 2022042 | 2583798 | 5887929 | ▇▇▃▁▁ |
| sales | CZ | Software | 0 | 1 | 732608 | 362912.3 | 65362.00 | 467194.5 | 766223 | 958775 | 1725191 | ▅▆▇▃▁ |
| sales | PL | Accessories | 0 | 1 | 78044 | 51826.0 | 8974.00 | 23275.9 | 79225 | 111939 | 241820 | ▇▇▅▂▁ |
| sales | PL | Components | 0 | 1 | 30040 | 28792.4 | 223.55 | 8053.0 | 18273 | 46259 | 123354 | ▇▂▂▁▁ |
| sales | PL | Monitors | 0 | 1 | 83086 | 71495.8 | 6584.10 | 30301.5 | 61357 | 106836 | 335074 | ▇▂▁▂▁ |
| sales | PL | Notebooks | 0 | 1 | 86742 | 72731.1 | 10958.20 | 33772.1 | 58830 | 123400 | 350005 | ▇▂▁▁▁ |
| sales | PL | PCs | 0 | 1 | 187843 | 103835.2 | 40870.00 | 95534.7 | 178289 | 246367 | 506350 | ▇▇▅▂▁ |
| sales | PL | Software | 0 | 1 | 57589 | 37629.3 | 10308.00 | 23788.0 | 45353 | 90604 | 158629 | ▇▅▂▂▁ |
| sales | SK | Accessories | 0 | 1 | 19315 | 11660.1 | 2658.80 | 5078.0 | 22104 | 28486 | 45877 | ▇▂▇▅▁ |
| sales | SK | Components | 0 | 1 | 11333 | 10258.7 | 142.80 | 2873.5 | 6852 | 18190 | 49780 | ▇▃▂▁▁ |
| sales | SK | Monitors | 0 | 1 | 37321 | 22694.9 | 3903.20 | 12826.0 | 39531 | 53260 | 92098 | ▇▃▆▃▂ |
| sales | SK | Notebooks | 0 | 1 | 42568 | 37129.4 | 4176.90 | 15323.9 | 29436 | 55498 | 184205 | ▇▃▁▁▁ |
| sales | SK | PCs | 0 | 1 | 56910 | 35174.6 | 12548.00 | 27890.5 | 48991 | 73774 | 195893 | ▇▅▂▁▁ |
| sales | SK | Software | 0 | 1 | 14408 | 8207.1 | 1457.75 | 6910.4 | 13659 | 21062 | 34416 | ▇▅▆▅▂ |
Čistenie a transformácia dát
Cieľom je upraviť dáta pre analýzu časových radov:
- Upraviť predaje podľa inflácie a výmenných kurzov. Táto úprava umožní lepšie porovnávanie predajov v rôznych časových obdobiach a krajinách. Inflácia ovplyvňuje nominálne hodnoty predajov, a preto ich úprava umožní lepšie pochopiť reálny rast či pokles predaja. Prepočet na rovnaký základ zabezpečí, že časový rad nebude ovplyvnený menovými výkyvmi.
- Prekonvertovať predaje na jednotnú menu (EUR). Vďaka tomuto kroku môžeme vykonať konzistentnú analýzu predajov v rôznych krajinách na jednotnej škále.
- Stabilizovať rozptyl pomocou logaritmickej transformácie. Pomáha redukovať extrémne hodnoty, čím znižuje vplyv sezónnych výkyvov a veľkých rozdielov medzi nízkymi a vysokými predajmi. Okrem toho premieňa multiplikatívnu sezónnosť na aditívnu, čo uľahčuje analýzu a modelovanie časových radov. Stabilizácia rozptylu je dôležitá pre modely ako ARIMA alebo ETS, ktoré vyžadujú približne stacionárne dáta.
- Odstránenie nepotrebných stĺpcov a transformácia na formát tsibble.
Kód
data_cleaned <- data |>
mutate(
# Konverzia dátumu na posledný deň v mesiaci
date = ceiling_date(as.Date(date), "month") - 1
) |>
# Pripojenie dát o výmennom kurze a CPI
left_join(cur_CZK, by = "date") |>
left_join(cur_PLN, by = "date") |>
left_join(CPI_eur, by = "date") |>
left_join(CPI_czech_rep, by = "date") |>
left_join(CPI_poland, by = "date") |>
mutate(
# Konverzia date na rok-mesiac (yearmonth) pre TS
date = yearmonth(date),
# Konverzia predajov (sales) do EUR
sales_EUR = round(case_when(
country == "PL" ~ sales * PLN,
country == "CZ" ~ sales * CZK,
TRUE ~ sales
)),
# Očistenie predajov o infláciu pomocou CPI
sales_EUR_CPI_adj = round(case_when(
country == "PL" ~ sales_EUR / CPI_poland * 100,
country == "CZ" ~ sales_EUR / CPI_czech * 100,
TRUE ~ sales_EUR / CPI_euro * 100
))
) |>
# Odstránenie nepotrebných stĺpcov
select(-sales, -CZK, -PLN, -CPI_poland, -CPI_czech, -CPI_euro)
# Konverzia na tsibble pre časovú analýzu
data_cleaned <- data_cleaned |>
as_tsibble(
key = c(country, division, channel, product_group),
index = date
)Vizualizácia trendov predaja
Vizualizácia nám pomáha pochopiť, ako sa predaje menili v čase, identifikovať trendy, sezónnosť a možné anomálie. Hoci sa môže zdať, že jednoduché nakreslenie časovej krivky je „amatérsky“ alebo nie príliš sofistikovaný prístup, v skutočnosti ide o jednu z najdôležitejších a najúčinnejších metód na pochopenie dát. Grafická analýza často odhalí vzory, ktoré by inak zostali skryté v číselných agregátoch alebo štatistických modeloch. Dobre zvolená vizualizácia dokáže rýchlo upozorniť na kľúčové momenty, ako sú prudké poklesy alebo nárasty predajov, sezónne výkyvy či štrukturálne zlomy, a pomáha formovať ďalšie analytické kroky.
Kód
ggplot(data_cleaned |> filter(year(date) >= 2022), aes(x = date, y = sales_EUR, color = product_group)) +
geom_line() +
facet_wrap(division ~ country ~ channel, scales = "free",
ncol = 2) +
labs(
title = "Predajné trendy po krajine, divízii a predajnom kanáli",
x = "Dátum",
y = "Predaj (EUR)"
) +
scale_y_continuous(labels = function(x) format(x, big.mark = " ", scientific = FALSE))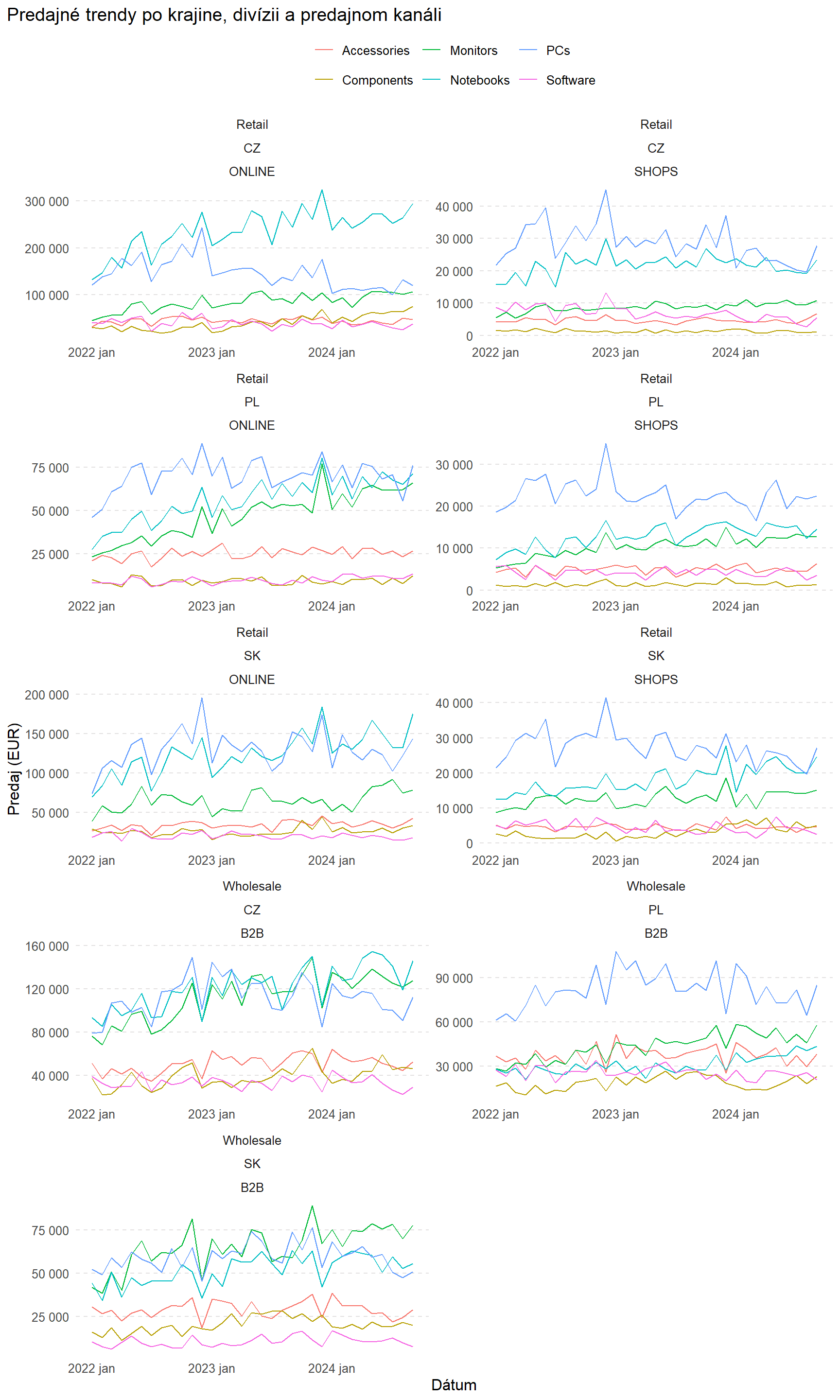
Pozorovania:
- V rôznych krajinách a kanáloch predaja môžu byť rôzne trendy.
- V ČR môže byť vidieť určitý pokles, zatiaľ čo v Poľsku rast.
- Predaje v kamenných predajniach (ak máme takýto kanál) môžu byť stabilné, ale nižšie ako v online.
- Potenciálnu sezónnosť (napr. pred Vianocami) je vhodné ďalej preskúmať.
Pre forecasty a prípadné vytváranie hierarchických časových radov je užitočné dáta sumarizovať na rôznych úrovniach. K tomu nám slúži funkcia aggregate_key(). Takto získame napr. sumu predajov (EUR) a očistených predajov (EUR_CPI_adj) pre rôzne úrovne hierarchie (krajina, divízia, kanál, produkt).
Kód
data_cleaned_agg <- data_cleaned |>
aggregate_key(
(country / division / channel) * product_group,
sales_EUR = sum(sales_EUR),
sales_EUR_CPI_adj = sum(sales_EUR_CPI_adj)
)Vizualizácia adjustovaných predajov a stabilizácia rozptylu
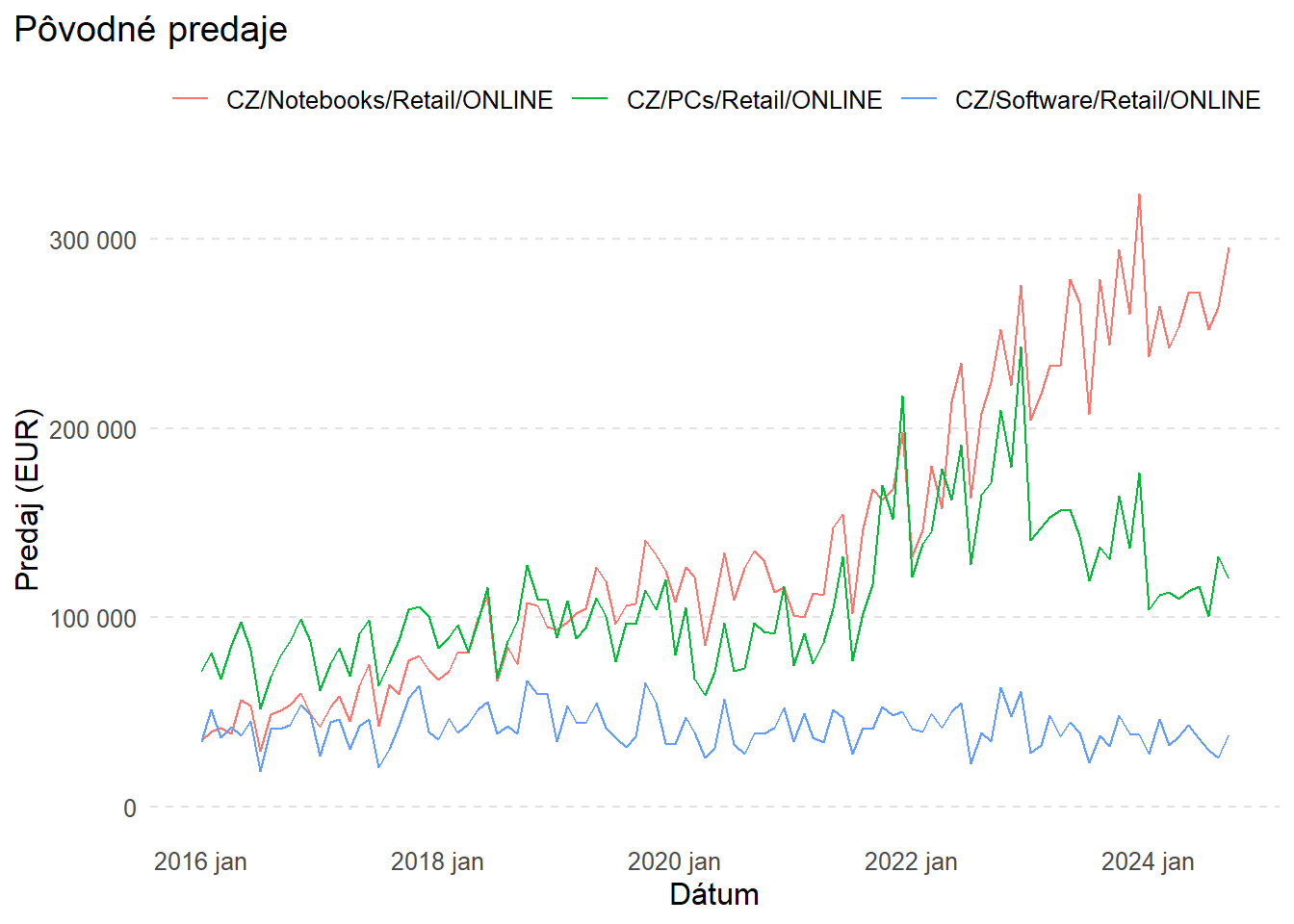
Porovnanie pôvodných predajov a CPI-očistených
Najprv si zistíme maximálnu hodnotu predajov v zvolenej podskupine, aby sme zachovali rovnakú mierku na grafoch.
Kód
max_sales_EUR <- data_cleaned_agg |>
filter(
country == "CZ",
channel == "ONLINE",
product_group %in% c("PCs", "Notebooks", "Software")
) |>
slice_max(order_by = sales_EUR, n = 1) |>
pull(sales_EUR)
data_cleaned_agg |>
filter(
country == "CZ",
channel == "ONLINE",
product_group %in% c("PCs", "Notebooks", "Software")
) |>
autoplot(sales_EUR) +
scale_y_continuous(labels = function(x) format(x, big.mark = " ", scientific = FALSE),
limits = c(0, max_sales_EUR)) +
labs(
x = "Dátum",
y = "Predaj (EUR)",
title = "Pôvodné predaje"
)
Kód
data_cleaned_agg |>
filter(
country == "CZ",
channel == "ONLINE",
product_group %in% c("PCs", "Notebooks", "Software")
) |>
autoplot(sales_EUR_CPI_adj) +
scale_y_continuous(labels = function(x) format(x, big.mark = " ", scientific = FALSE),
limits = c(0, max_sales_EUR)) +
labs(
x = "Dátum",
y = "Predaj (EUR, CPI Adj.)",
title = "CPI adjustované predaje"
)
Z porovnania grafov je zrejmé, že rast predaja notebookov je pred úpravou príliš optimistický a do značnej miery sú vyššie predaje dôsledkom inflácie.
Stabilizácia rozptylu (log transformácia)
Pri časových radoch, ktoré majú rastúci trend alebo veľké rozdiely v hodnotách, môže logaritmická transformácia pomôcť stabilizovať rozptyl.
Kód
# Pred log-transformáciou
data_cleaned_agg |>
filter(
country == "CZ",
channel == "ONLINE",
product_group == "Notebooks"
) |>
autoplot(sales_EUR) +
scale_y_continuous(labels = function(x) format(x, big.mark = " ", scientific = FALSE)) +
labs(
x = "Dátum",
y = "Predaj (EUR)"
)
Kód
# Po log-transformácii
data_cleaned_agg |>
filter(
country == "CZ",
channel == "ONLINE",
product_group == "Notebooks"
) |>
autoplot(log(sales_EUR)) +
labs(
x = "Dátum",
y = "Predaj (EUR, log-trans.)"
)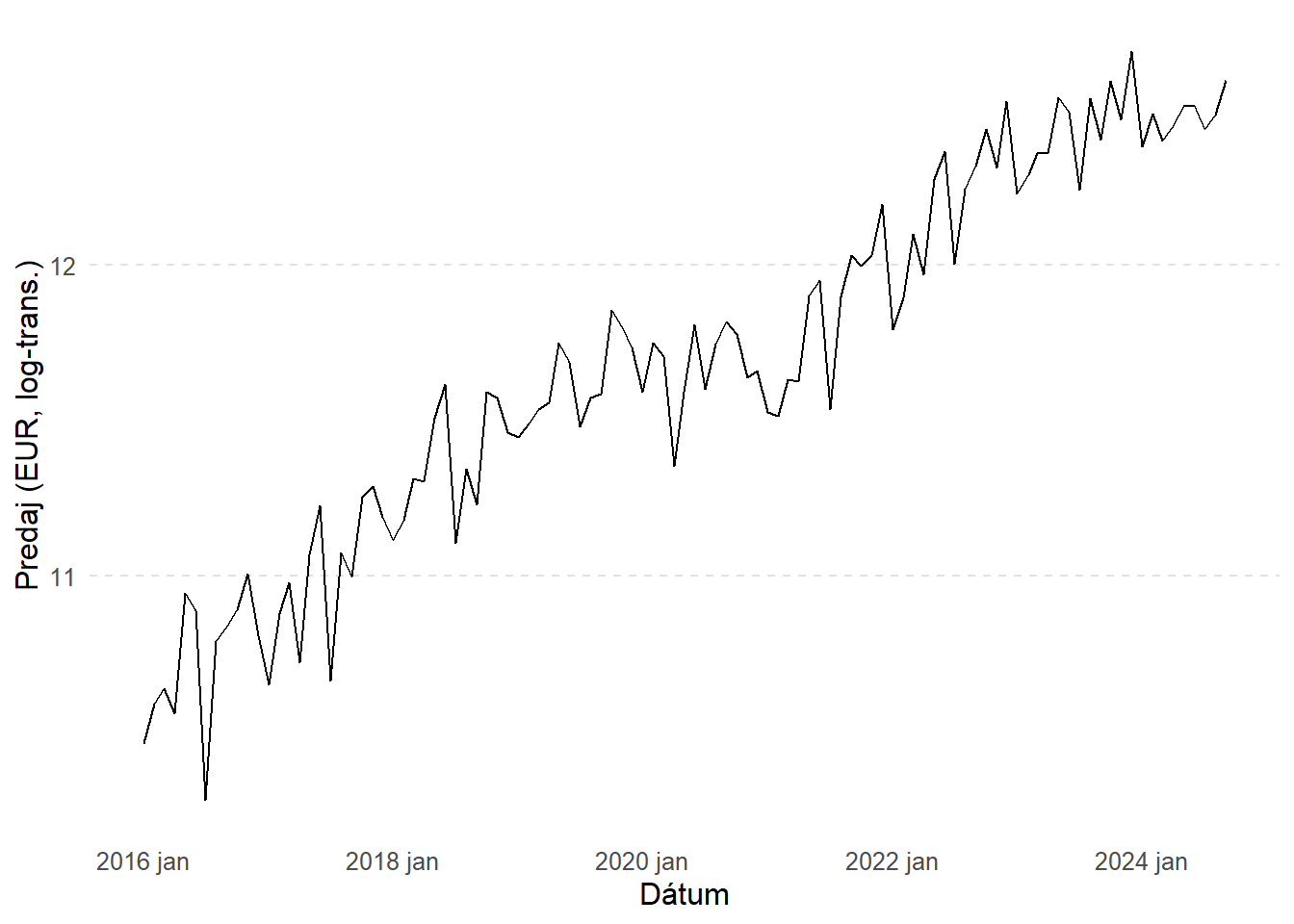
Použitie logaritmickej transformácie má niekoľko výhod. Najčastejšie sa používa za účelom:
- Odstránenia efektu rastúcich sezónnych výkyvov (multiplikatívna sezónnosť) – tento jav nastáva, keď sú sezónne výkyvy závislé od úrovne samotného časového radu – čím vyššia je hodnota radu, tým väčšie sú absolútne sezónne fluktuácie.
- Zlepšuje stacionaritu – redukuje rastúci trend a stabilizuje rozptyl, čo je dôležité pre modely ako ARIMA, ktoré vyžadujú stacionárne dáta.
- Mení interpretáciu – rozdiely v logaritmovanom rade odpovedajú percentuálnym zmenám v pôvodnom rade.
Ak po logaritmickej transformácii sezónnosť stále nie je aditívna, ďalším krokom môže byť diferenciácia.
Sezónnosť a dekompozícia časových radov
Teraz si ukážeme, ako rozložiť (dekomponovať) časovú radu na trend, sezónnu a reziduálnu (náhodnú) zložku pomocou metódy STL (Seasonal and Trend decomposition using Loess). Používa LOESS (Local Regression Smoothing) na vyhladenie trendu a sezónnosti.
STL má oproti iným metódam (napr. klasická dekompozícia alebo X-13-ARIMA-SEATS) výhody ako:
- Flexibilná sezónnosť – umožňuje zmenu sezónnych vzorcov v čase
- Robustnosť voči outlierom – lepšie zvláda extrémne hodnoty
- Možnosť nastaviť parametre trendu a sezónnosti (dĺžku časového okna) – umožňuje jemnejšiu kontrolu nad výsledkami
V našom príklade použijeme parametre:
- trend(window = 21) – trendová zložka sa vyhladzuje pomocou LOESS s oknom 21 období (ide o mesačné dáta, trend sa teda vypočítava na 21-mesačnej perióde). Väčšie okno znamená hladšiu krivku trendu.
- season(window = “periodic”) – sezónnosť sa modeluje ako plne periodická, čo znamená, že metóda využije všetky dostupné údaje na určenie sezónnych vzorcov.
STL sa používa napr pri detektcii odľahlých hodnôt alebo keď potrebujeme očistiť časový rad od sezónnosti (a trendu) pred ďalšou analýzou (napr. forecasting modely založené na ML).
Kód
dcmp <- data_cleaned_agg |>
filter(
country == "SK",
channel == "ONLINE",
product_group == "PCs"
) |>
model(
stl = STL(sales_EUR ~ trend(window = 21) + season(window = "periodic"))
)
components(dcmp) |>
autoplot() +
scale_y_continuous(labels = function(x) format(x, big.mark = " ", scientific = FALSE)) +
labs(x = "Dátum")
Zároveň si môžeme zistiť štatistické vlastnosti (features) časových radov a pozrieť, ktoré série majú najsilnejší alebo najslabší trend či sezónnosť.
Popis jednotlivých STL Features (z funkcie feat_stl()):
- trend_strength – Udáva, aký veľký podiel variability v časovom rade vysvetľuje trendová zložka. Hodnota sa pohybuje medzi 0 a 1 – vyššie hodnoty znamenajú silný trend. Ak sa hodnota blíži k 1, dáta majú výrazný dlhodobý trend. Ak sa hodnota blíži k 0, trend je minimálny.
- seasonal_strength – Udáva, aký veľký podiel variability vysvetľuje sezónna zložka. Hodnota sa pohybuje medzi 0 a 1 – čím vyššia hodnota, tým výraznejšia sezónnosť. Ak sa blíži k 0, časový rad nemá sezónne vzory.
- spikiness – Meria krátkodobú volatilitu v zvyškovej (reziduálnej) zložke časového radu. Vyššie hodnoty znamenajú výraznejšie neočakávané výkyvy, ktoré nie sú vysvetlené trendom ani sezónnosťou. Používa sa na identifikáciu prítomnosti anomálií alebo šokov v dátach.
- peak – Identifikuje, v ktorom čase v rámci sezónneho cyklu nastáva najvyšší bod sezónnosti. Napríklad, v prípade mesačných dát, peak = 6 znamená, že predaje sú najvyššie v Júni.
- trough – Identifikuje, v ktorom čase v rámci sezónneho cyklu nastáva najnižší bod sezónnosti. Napríklad, v prípade mesačných dát, trough = 1, znamená, že predaje sú najnižšie v Januári.
- linearity – Udáva, ako lineárny je trend časového radu. Vyššie hodnoty znamenajú silnejšiu lineárnu zložku trendu (stály rast alebo pokles). Hodnota blížiaca sa k 0 znamená, že trend nie je výrazne lineárny, ale môže byť cyklický alebo stacionárny.
- curvature – Meria zakrivenie trendu – teda ako veľmi sa mení jeho sklon. Vyššie hodnoty znamenajú nelineárne trendy (napr. zrýchľujúci rast alebo spomalenie poklesu). Ak sa hodnota blíži k 0, trend je takmer priamka.
- stl_e_acf1 – Prvá autokorelácia reziduálov (zvyškov časového radu). Meria, do akej miery sú dnešné odchýlky od trendu a sezónnosti závislé od predchádzajúcich hodnôt. Ak sa hodnota blíži k 1, znamená to silnú časovú závislosť v reziduálnej zložke.
- stl_e_acf10 – Súčet štvorcov prvých desiatich autokorelácií reziduálnej zložky. Namiesto jednej hodnoty autokorelácie (ako pri stl_e_acf1) táto metrika sumarizuje celkovú autokorelačnú štruktúru reziduálov do oneskorenia (lag) 10.
Všetky tieto metriky majú svoje praktické využitie napr. pri výbere vhodného modelu, detekcii prítomnosti anomálií, interpretácii sezónnych vzorov. Nízke hodnoty stl_e_acf1 a stl_e_acf10 ukazujú, že reziduá sú takmer náhodné a STL dobre rozdelila časový rad na trend a sezónnosť. Naopak, ak sú vysoké, V reziduálnej zložke ostáva autokorelačná štruktúra – môže ísť o nezachytený trend alebo cyklus. Vtedy môže byť potrebné lepšie nastaviť trendové/sezónne okno v STL, napr. experimentovať s rôznymi hodnotami trend(window = X) a season(window = Y).
Kód
stl_features <- data_cleaned |>
features(sales_EUR, feat_stl)
stl_features
#> # A tibble: 54 × 13
#> country division channel product_group trend_strength seasonal_strength_year
#> <chr> <chr> <chr> <chr> <dbl> <dbl>
#> 1 CZ Retail ONLINE Accessories 0.906 0.755
#> 2 CZ Retail ONLINE Components 0.952 0.502
#> 3 CZ Retail ONLINE Monitors 0.968 0.645
#> 4 CZ Retail ONLINE Notebooks 0.981 0.674
#> 5 CZ Retail ONLINE PCs 0.908 0.754
#> 6 CZ Retail ONLINE Software 0.287 0.647
#> 7 CZ Retail SHOPS Accessories 0.655 0.678
#> 8 CZ Retail SHOPS Components 0.535 0.388
#> 9 CZ Retail SHOPS Monitors 0.733 0.559
#> 10 CZ Retail SHOPS Notebooks 0.826 0.416
#> # ℹ 44 more rows
#> # ℹ 7 more variables: seasonal_peak_year <dbl>, seasonal_trough_year <dbl>,
#> # spikiness <dbl>, linearity <dbl>, curvature <dbl>, stl_e_acf1 <dbl>,
#> # stl_e_acf10 <dbl>Trend a sezónnosť
Trend
Nižšie ilustrujeme, ako nájsť a zobraziť sériu s minimálnou a maximálnou silou trendu.
Skúmanie autokorelačných vzorcov:
Kód
# Minimálna a maximálna sila trendu
trend_strength_min <- stl_features |>
filter(trend_strength == min(trend_strength))
trend_strength_max <- stl_features |>
filter(trend_strength == max(trend_strength))
# Príklad zobrazenia série s minimálnou silou trendu
data_cleaned_agg |>
filter(
country == "CZ",
channel == "ONLINE",
product_group == "Software"
) |>
autoplot(sales_EUR) +
scale_y_continuous(labels = function(x) format(x, big.mark = " ", scientific = FALSE), limits = c(0, 80000)) +
labs(
title = "Časový rad s najslabším trendom",
x = "Dátum",
y = "Predaj (EUR)"
)
Kód
# Príklad zobrazenia série s maximálnou silou trendu
data_cleaned_agg |>
filter(
country == "PL",
channel == "ONLINE",
product_group == "Monitors"
) |>
autoplot(sales_EUR) +
scale_y_continuous(labels = function(x) format(x, big.mark = " ", scientific = FALSE), limits = c(0, 80000)) +
labs(
title = "Časový rad s najsilnejším trendom",
x = "Dátum",
y = "Predaj (EUR)"
)
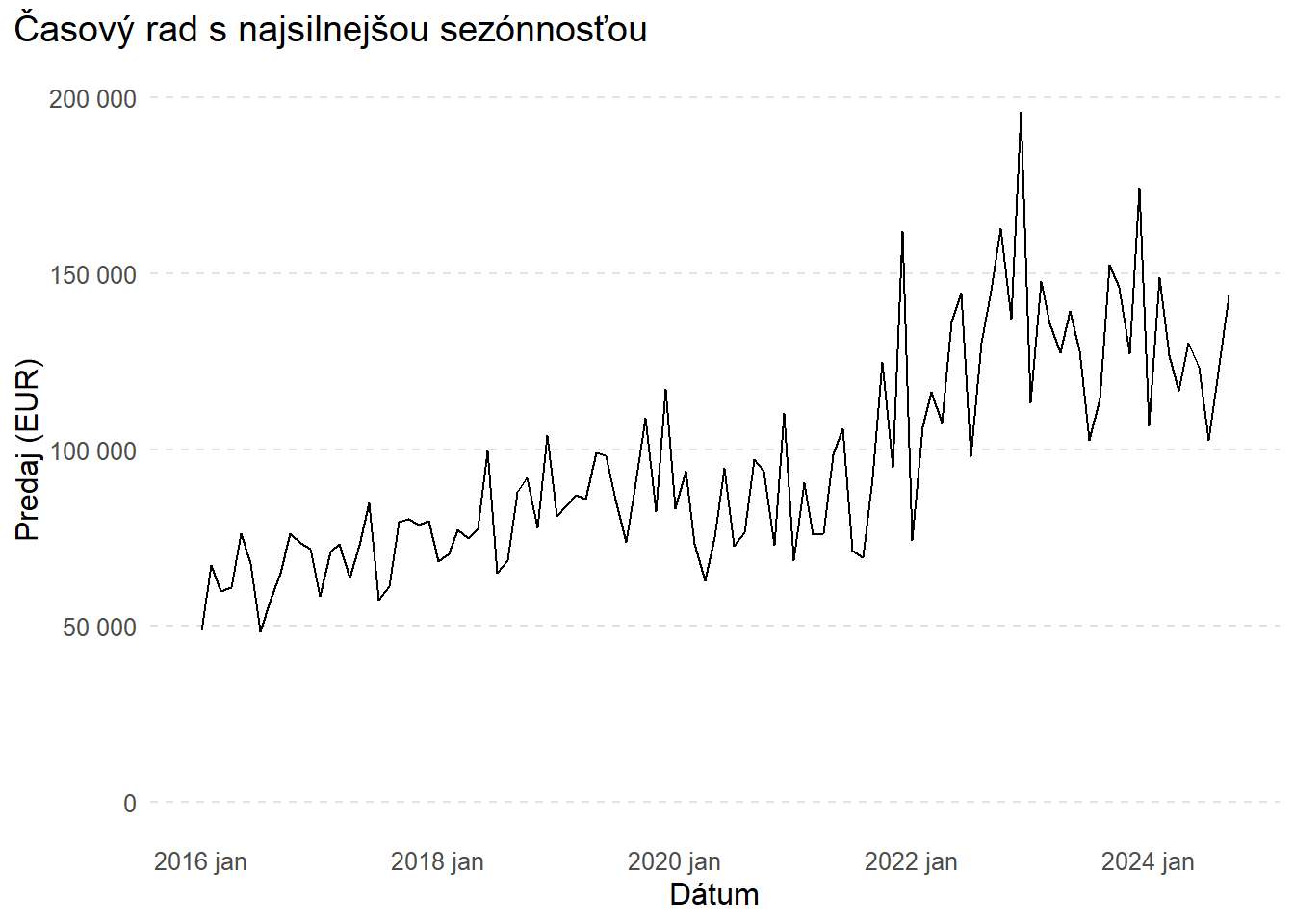
Sezónnosť
Rovnako postupujeme pri sezónnosti
Kód
# Minimálna a maximálna sezónnosť
season_strength_min <- stl_features |>
filter(seasonal_strength_year == min(seasonal_strength_year))
season_strength_max <- stl_features |>
filter(seasonal_strength_year == max(seasonal_strength_year))
# Zobrazenie série s minimálnou sezónnosťou
data_cleaned_agg |>
filter(
country == "SK",
channel == "B2B",
product_group == "Components"
) |>
autoplot(sales_EUR) +
scale_y_continuous(labels = function(x) format(x, big.mark = " ", scientific = FALSE), limits = c(0, 200000)) +
labs(
title = "Časový rad s najslabšou sezónnosťou",
x = "Dátum",
y = "Predaj (EUR)"
)
Kód
# Zobrazenie série s maximálnou sezónnosťou
data_cleaned_agg |>
filter(
country == "SK",
channel == "ONLINE",
product_group == "PCs"
) |>
autoplot(sales_EUR) +
scale_y_continuous(labels = function(x) format(x, big.mark = " ", scientific = FALSE), limits = c(0, 200000)) +
labs(
title = "Časový rad s najsilnejšou sezónnosťou",
x = "Dátum",
y = "Predaj (EUR)"
)
Knižnice fable a feasts umožňujú rýchlo vytvárať sezónne grafy (gg_season()) a sub-série (gg_subseries()).
Funkcia gg_season() umožňuje vizualizovať sezónnosť v časovom rade tým, že zobrazuje jednotlivé sezónne cykly na jednom grafe. To znamená, že dáta sú rozdelené podľa sezónneho obdobia (napr. mesiace v roku, dni v týždni) a zobrazené pre všetky dostupné roky, čo uľahčuje porovnanie sezónnych trendov naprieč rôznymi obdobiami.
Interpretácia:
- Každá čiara predstavuje jeden rok, pričom osi X zobrazujú sezónne obdobie (jednotlivé mesiace).
- Umožňuje vidieť opakovateľné vzory – napr. kedy majú predaje tendenciu rásť alebo klesať.
- Ak sú všetky roky veľmi podobné, znamená to stabilnú sezónnosť.
- Ak sú medzi jednotlivými rokmi veľké rozdiely, sezónnosť môže byť nestabilná alebo meniaca sa v čase.
Kód
# Retail - Online
data_cleaned_agg |>
filter(
is_aggregated(product_group),
country == "CZ",
division == "Retail",
channel == "ONLINE"
) |>
gg_season(sales_EUR) +
scale_y_continuous(labels = function(x) format(x, big.mark = " ", scientific = FALSE)) +
labs(
x = "Mesiac",
y = "Predaj (EUR)",
title = "Sezónnosť predajov v divízii Retail - Online Predaje (CZ)"
)
Kód
# B2B
data_cleaned_agg |>
filter(
is_aggregated(product_group),
country == "CZ",
channel == "B2B"
) |>
gg_season(sales_EUR) +
scale_y_continuous(labels = function(x) format(x, big.mark = " ", scientific = FALSE)) +
labs(
x = "Mesiac",
y = "Predaj (EUR)",
title = "Sezónnosť predajov v divízii B2B (CZ)"
)
Funkcia gg_subseries() rozkladá časový rad na jednotlivé sezónne obdobia, pričom každý sezónny cyklus je znázornený ako samostatná séria. Toto je užitočné na podrobnejšiu analýzu sezónnych vzorov, pretože umožňuje zistiť, či sezónnosť ostáva konzistentná alebo sa v priebehu času mení.
Interpretácia:
- Na osi X sú sezónne obdobia (napr. mesiace v roku).
- Každý box predstavuje priemernú hodnotu predaja pre dané obdobie v rôznych rokoch.
- Sub-sériové grafy umožňujú lepšie pochopiť, ako sa sezónnosť vyvíja v priebehu času.
- Ak niektoré mesiace vykazujú veľké výkyvy medzi rokmi, sezónne efekty sa môžu meniť a treba ich modelovať dynamicky.
Kód
data_cleaned_agg |>
filter(
country == "CZ",
channel == "ONLINE",
is_aggregated(product_group)
) |>
gg_subseries(sales_EUR) +
scale_y_continuous(labels = function(x) format(x, big.mark = " ", scientific = FALSE)) +
labs(
x = "Mesiac",
y = "Predaj (EUR)",
title = "Subseries graf pre Retail - Online predaje (CZ)"
)
Autokorelácia
Autokorelácia odhaľuje, či (a do akej miery) závisia hodnoty v čase od svojich predchádzajúcich hodnôt. Inými slovami, skúma vzťah medzi hodnotami časového radu v rôznych časových bodoch a pomáha identifikovať vzorovosť, cykly a dlhodobé vzťahy v dátach.
Autokorelácia pri oneskorení (lag) k sa vypočíta ako Pearsonov korelačný koeficient medzi pôvodným časovým radom a jeho posunutou hodnotou. Ak má vysoké hodnoty (pozitívne alebo negatívne), naznačuje trend alebo systematický vzor v dátach. Ak sa autokorelácia blíži k nule časový rad nemá vzorovú štruktúru a správa sa ako šum (random noise). Hodnoty autokorelácie pomáhajú detekovať trendy a sezónne vzory v časových radoch, sú základným vstupom pri výbere správneho štatistického modelu a umožňujú diagnostikovať modely – reziduá dobrého modelu by mali mať nízku autokoreláciu.
Okrem ACF (autocorrelation function) je dôležitým ukazovateľom aj PACF (partial autocorrelation function), ktorý meria koreláciu medzi hodnotou a jej lagovaných hodnôt po odstránení efektu ostatných lagovaných hodnôt. Používa sa pri výbere autoregresívnych (AR) modelov v ARIMA rodine modelov.
Kód
# Autocorrelation Function (ACF)
data_cleaned |>
filter(
country == "SK",
channel == "ONLINE",
product_group == "PCs"
) |>
ACF(sales_EUR) |>
autoplot()
Kód
# Partial Autocorrelation Function (PACF)
data_cleaned |>
filter(
country == "SK",
channel == "ONLINE",
product_group == "PCs"
) |>
PACF(sales_EUR) |>
autoplot()
Diferencovanie
Diferencovanie je technika používaná na odstránenie trendovej a sezónnej zložky z časového radu. Je dôležité najmä pri modeloch ako ARIMA, ktoré vyžadujú stacionárne dáta (t.j. bez systematického rastu alebo poklesu v čase). Diferencovanie nahrádza pôvodné hodnoty časového radu rozdielom medzi hodnotou v čase t a t-1. Ak existuje sezónna zložka, môžeme použiť sezónne diferencovanie, kde sa odpočítava hodnota z predchádzajúceho sezónneho obdobia (napr. pri mesačných dátach odpočítavame hodnotu spred 12 mesiacov).
Kód
data_diff <- data_cleaned |>
filter(
country == "SK",
channel == "ONLINE",
product_group == "PCs"
) |>
mutate(diff_sales = difference(sales_EUR))
data_diff |>
autoplot(diff_sales) +
labs(
x = "Dátum",
y = "Diferencované predaje (EUR)"
)
Či bolo diferencovanie úspešné zistíme pomocou vizualizácie diferenciovaného radu, aplikovaním ACF (ak je diferencovaný rad stacionárny, ACF by mala rýchlo klesať na nulu) alebo pomocou Dickey-Fullerovho testu stacionarity.
Detekcia anomálií
Anomália je bod alebo skupina bodov, ktoré nejakým spôsobom nezapadajú do normálneho alebo očakávaného rozsahu hodnôt. Nie každá anomália je však nežiaduca. Hoci niektoré vznikajú napríklad v dôsledku chýb v meraní, iné môžu byť výsledkom špecifickej situácie v procese, ktorá môže mať vysokú výpovednú hodnotu. V literatúre aj praxi sa preto používajú rôzne označenia pre anomálie, napríklad outliers (odľahlé hodnoty), novelties, či noise (šum). Podľa kontextu sa odlišuje aj spôsob práce s anomáliami. Ak ide o chyby, najlepším riešením je tieto hodnoty odstrániť (napr. nahradením). Ak však predstavujú dôsledok dôležitých udalostí (napr. zmena správania, zlyhanie zariadenia a pod.), môžu slúžiť ako základ pre ďalšiu analýzu.
V prípade časových radov je situácia ešte zložitejšia, pretože v niektorých prípadoch nie je anomália definovaná iba svojou hodnotou, ale aj zmenou vo vzorci (časovaní). Príkladom môže byť EKG pacienta s arytmiou – v tomto prípade je anomália definovaná nepravidelnosťou medzi údermi srdca, nie samotnou hodnotou elektrickej aktivácie.
Existuje viacero prístupov a množstvo odborných článkov venujúcich sa detekcii anomálií. Medzi základné metódy patria:
- IQR (Interquartile Range) – Anomálie sú definované ako hodnoty ležiace mimo interkvartilného rozpätia, typicky 1,5×IQR od prvého (Q1) a tretieho (Q3) kvartilu.
- GESD (Generalized Extreme Studentized Deviate Test) – Iteratívna metóda identifikácie odľahlých hodnôt na základe štatistických testov.
- Pokročilé metódy – Napríklad Twitter/STS (Seasonal-Trend Decomposition), algoritmy strojového učenia ako Isolation Forest, DBSCAN a ďalšie. Tieto metódy však presahujú rámec tohto blogu.
Viac informácií môžete nájsť napr. v tomto článku.
V nasledujúcom príklade použijeme STL dekompozíciu v kombinácii s metódou IQR. Funkcia time_decompose() rozloží časovú radu na trend, sezónnosť a zvyšky (remainders). Následne anomalize() detekuje anomálie práve vo zvyškoch a time_recompose() umožní opätovné zloženie časovej rady.
Kód
ts_anomalize <- data_cleaned_agg |>
as_tibble() |>
mutate(date = as.Date(date)) |>
filter(country == "SK", channel == "ONLINE", product_group == "PCs") |>
time_decompose(sales_EUR, method = "stl") |>
anomalize(remainder, method = "iqr", alpha = 0.1) |>
time_recompose()
plot_anomalies(ts_anomalize)
Záver
V tomto blogu sme prešli základný proces exploratívnej analýzy časových radov (EDA) s dôrazom na čistenie, transformáciu, vizualizáciu a detekciu anomálií. Hlavné kroky zahŕňali:
- Načítanie a kontrolu dát – overenie úplnosti, pravidelnosti a príprava údajov na analýzu.
- Čistenie a transformáciu – očistenie predajov o infláciu, konverzia do jednotnej meny a stabilizácia rozptylu.
- Vizualizáciu – analýzu trendov, sezónnosti a identifikáciu vzorov v predajoch.
- Dekompozíciu časových radov (STL) – rozklad série na trendovú, sezónnu a reziduálnu zložku.
- Autokoreláciu (ACF, PACF) – skúmanie časových vzťahov a závislostí v dátach.
- Diferencovanie – odstránenie trendu a sezónnosti pre získanie stacionárnych časových radov.
- Detekciu anomálií – identifikáciu neobvyklých bodov pomocou IQR a STL dekompozície.
Tieto postupy sú kľúčové pri analýze časových radov a nachádzajú široké uplatnenie v mnohých odvetviach a vedných odboroch. Pomáhajú lepšie porozumieť historickým trendom, predikovať budúci vývoj a identifikovať nečakané výkyvy v dátach.
V ďalšej časti sa zameriame na clustrovanie časových radov, kde budeme segmentovať rôzne časové rady na základe ich priebehu alebo štatistických charakteristík. Následne sa budeme venovať forecastovaniu: ukážeme využitie tradičných metód (ARIMA, ETS) a zároveň predstavíme možnosti strojového učenia (napr. gradient boosting). Porovnáme, v čom sa tieto prístupy odlišujú a na aké situácie sú vhodné.
Referencie
Viac informácií o spomínaných metódach nájdete v:
- Hyndman, R.J., & Athanasopoulos, G. (2021) Forecasting: principles and practice, 3rd edition, OTexts: Melbourne, Australia. OTexts.com/fpp3
- Boniol, Paul & Liu, Qinghua & Huang, Mingyi & Palpanas, Themis & Paparrizos, John. (2024). Dive into Time-Series Anomaly Detection: A Decade Review. 10.48550/arXiv.2412.20512
- Dokumentácia ku knižniciam: tsibble, fable, feasts, anomalize a timetk.
You might also like
-
Ako zrýchliť XGBoost v R: Benchmark trénovania modelu na CPU vs. GPU https://cleandata.sk/wp-content/themes/engic/images/empty/thumbnail.jpg 150 150 cleandata https://secure.gravatar.com/avatar/ee96a699da7fa28e99fc6752011335df?s=96&d=mm&r=g

-
susR: Zjednodušenie práce s dátami Štatistického úradu SR v R https://cleandata.sk/wp-content/themes/engic/images/empty/thumbnail.jpg 150 150 cleandata https://secure.gravatar.com/avatar/ee96a699da7fa28e99fc6752011335df?s=96&d=mm&r=g
-
Ako vytvoriť interaktívny dashboard v R pomocou Quarto https://cleandata.sk/wp-content/themes/engic/images/empty/thumbnail.jpg 150 150 cleandata https://secure.gravatar.com/avatar/ee96a699da7fa28e99fc6752011335df?s=96&d=mm&r=g

Leave a Reply