Ako vytvoriť API v R pomocou knižnice Plumber
V tomto blogu vám predstavím Plumber – knižnicu v R, ktorá umožňuje jednoducho vytvárať webové API z vašich R skriptov a modelov. Ukážem, ako môžete svoje modely sprístupniť programovo a ako ich nasadiť do produkcie pomocou Dockeru, čím sprístupníte výsledky svojej práce širšej skupine používateľov.
Úvod
Často sa stretávam s tvrdením, že Python je jedinou správnou voľbou pre produkčné nasadenie modelov a aplikácií. R býva označované ako nástroj, ktorého miesto je v akadémii alebo je síce výborný na dátovú analýzu a štatistické výpočty, ale v produkcii nie je použiteľný. Toto tvrdenie však nemusí byť pravdivé ak sa venujete dátovej analýze alebo tradičnému strojovému učeniu. R je v týchto oblastiach silným hráčom vďaka moderným frameworkom ako Tidymodels a mlr3, ktoré nezaostávajú za Pythonom a v oblasti spracovania dát si dovolím povedať, že má dokonca navrch vďaka frameworku tidyverse. Niekto by mohol oponovať, že Python je rýchlejší. Hádajte čo. R ponúka napr. data.table, ktorý je rýchly a ak vám nevadí menší overhead, môžete použiť aj dtplyr, ktorý vám opäť ponúka tidy syntax. Mimochodom, všimli ste si, že Google prišiel s novou syntaxou pre SQL, ktorá používa “pipe operator”, rovnako ako R používa už roky? Škoda, že nikde nespomínajú túto inšpiráciu. Určite by to pomohlo popularizovať R medzi analytikmi a dátovými vedcami.
Ako však zabezpečiť, aby výsledky vašej práce v R boli ľahko dostupné aj kolegom bez nutnosti používať samotné R? Riešením je použitie API. V tomto blogu si predstavíme, ako jednoducho môžeme vytvoriť API pomocou knižnice Plumber. Ukážeme si konkrétny príklad nasadenia XGBoost modelu na predikciu cien bytov, ktorý bude dostupný cez webové rozhranie alebo programovo v kóde v zásade v ktoromkoľvek jazyku.
Čo je Plumber?
Plumber je R knižnica, ktorá umožňuje premeniť R skripty (od jednoduchých funkcií, cez komplexné transformácie až po rôzne objekty) na webové API. Týmto spôsobom môžete jednoducho poskytnúť výsledky vašej práce aj tým používateľom, ktorí nemusia pracovať v R a môžu využívať iné technológie či programovacie jazyky.
Na transformáciu kódu na API typicky používame špeciálne komentáre/anotácie označené pomocou #*, #* @param, #* @post (a iné endpointy, viď. nižšie), #* @serializer a i. Tie definujú správanie API a parametre, ktoré môžeme poskytnúť pri volaní API.
Endpointy
Endpointy sú špeciálne funkcie, ktoré definujú ako bude API reagovať na rôzne HTTP požiadavky. Napríklad, ak chcete vytvoriť endpoint pre GET požiadavku, môžete použiť #* @get /názov. Pre POST požiadavku použijete #* @post /názov. Viac informácií o HTTP metódach nájdete na restapitutorial.
Serializácia
Plumber podporuje rôzne formáty serializácie, ako sú JSON, CSV, HTML a ďalšie. Defaultne je nastavený JSON, ale môžete si zvoliť iný formát pomocou #* @serializer. Napríklad, ak chcete vrátiť odpoveď vo formáte CSV, môžete použiť #* @serializer csv. Medzi ďalšie formáty patria napr. parquet, html, pdf, jpeg, png a iné.
Programové volanie
Okrem tvorby API pomocou anotácií môžete vytvoriť API aj programovo. Na to slúži funkcia pr() (plumber router), ktorá vám umožňuje definovať API pomocou R6 objektov. Tento prístup je užitočný, ak potrebujete väčšiu flexibilitu a kontrolu.
Hooks
Plumber podporuje “hooks”, čiže špeciálne funkcie, ktoré sa vykonávajú pred alebo po spracovaní požiadavky. Tieto funkcie môžu byť použité na rôzne účely, ako napríklad autentifikácia, logovanie alebo spracovanie chýb.
Aktuálne sú podporované nasledujúce hooky: – preroute(data, req, res): vykoná sa pred spracovaním požiadavky – postroute(data, req, res, value): vykoná sa po spracovaní požiadavky – preserialize(data, req, res, value): vykoná sa pred serializáciou odpovede – postserialize(data, req, res, value): vykoná sa po serializácii odpovede
Filtre
Filtre sú špeciálne funkcie, ktoré modifikujú prichádzajúcu požiadavku, vrátia chybu alebo vrátia odpoveď predtým, ako požiadavka dosiahne endpoint. Sú užitočné na spracovanie vstupov, ako je napríklad overenie formátu alebo typov údajov. Rovnako môžu pridávať dodatočné informácie do požiadavky, napr. timestamp alebo unikátne ID relácie.
Každý filter musí obsahovať funkciu forward(). Tá je zodpovedná za predanie kontroly ďalšiemu filtru alebo endpointu. Ak sa táto funkcia nezavolá, predpokladá sa, že požiadavku spracoval sám a žiadny iný filter alebo endpoint nebude spracovávať túto požiadavku.
Kľúčovou vlastnosťou filtrov je, že nie všetky endpointy ich musia použiť.
Ďalšie info
Pre viac informácií o tvorbe API pomocou knižnice Plumber odporúčam navštíviť oficiálnu stránku. V sekcii “Articles” nájdete množstvo užitočných článkov a príkladov, ktoré vám pomôžu lepšie pochopiť, ako Plumber funguje. Okrem základných návodov tam nájdete aj články venujúce sa bezpečnosti, hostingu a nasadeniu API do produkcie.
Praktická ukážka
Tento projekt čiastočne nasledoval postup podľa série blogov od Jafara Aziza. Jeho kód nájdete na GitHube. Hlavný rozdieľ je v tom, že vytvárame len jednu API, zato však komplikovanejšiu, keďže sa jedná o integráciu ML modelu.
Štruktúra projektu
Naša ukážková aplikácia umožňuje predikovať cenu bytu podľa rôznych parametrov, ako je lokalita, rozloha, stav či typ bytu. je to rovnaký model ako sme použili v tomto blogu a Shiny aplikácii. Upozorňujem, že model bol trénovaný na dátach z konca roka 2023 a jeho predikcie sú len orientačné.
Štruktúra nášho projektu vyzerá nasledovne:
.
├── app.R
├── data
│ ├── bundled.RDS
│ ├── certificates.RDS
│ ├── conditions.RDS
│ ├── districts.RDS
│ ├── districts_mapping.RDS
│ ├── index.RDS
│ ├── latlon.RDS
│ ├── municipalities.RDS
│ └── types.RDS
├── docker-compose.yaml
├── Dockerfile
├── helpers
│ ├── logging.R
│ └── validator.R
└── logs
├── plumber_20250420_185501.log
└── plumber_20250421_094015.logV hlavnom skripte app.R načítavame model aj potrebné dáta (obe z priečinku data na diagrame), definujeme API endpointy a spúšťame samotné API. Na spracovanie vstupov využívame pomocné skripty.
Skript validator.R obsahuje funkcie na validáciu vstupných parametrov, ktoré sú volané v rámci API endpointov. Skript error.R obsahuje funkcie na spracovanie chýb a logovanie.R obsahuje funkcie na logovanie požiadaviek a odpovedí.
Skript logging.R obsahuje funkcie na logovanie požiadaviek a odpovedí. Tieto funkcie sú volané v rámci API endpointov a slúžia na sledovanie správania API a identifikáciu chýb. Na diagrame vidíme príklady .log súborov pod priečinkom “logs”, ktoré sa generujú pri spustení API. Tu treba povedať, že pri použitom deploymente sa tieto logy neukladajú a ich účel bol len pre identifikáciu chýb pri vývoji.
Nasadenie do GCP cez Docker
Pre nasadenie API do produkcie (na Google Cloud Platform) používame Docker, čo nám zaručuje, že aplikácia bude fungovať identicky lokálne aj v produkcii. Použitím docker-compose.yaml a Dockerfile máme jednoduchý spôsob ako API spustiť a spravovať v rôznych prostrediach.
Docker-compose.yaml súbor definuje jednoduchú konfiguráciu pre spustenie API služby v Docker kontajnery. Tento súbor obsahuje aj definíciu siete a portu, na ktorom bude API dostupné. V našom prípade je to port 8000.
version: '3'
services:
api:
build: .
container_name: predict
volumes:
- ./:/app
environment:
- PORT=${PORT:-8000}
- HOST=${HOST:-0.0.0.0}
ports:
- "8000:8000"Dockerfile obsahuje inštrukcie na vytvorenie Docker image, ktorý obsahuje všetky potrebné závislosti a knižnice pre spustenie API. Tento image je možné nasadiť na rôzne platformy.
FROM rocker/r-ver:latest
# install os dependencies
RUN apt-get update -qq
RUN apt-get install -y --no-install-recommends \
git-core \
libssl-dev \
libcurl4-gnutls-dev \
curl \
libsodium-dev \
libxml2-dev \
&& rm -rf /var/lib/apt/lists/*
# install pak alternatives to install.packages
RUN Rscript -e "install.packages('pak', repos = sprintf('https://r-lib.github.io/p/pak/stable'))"
# install latest plumber from github main branch
RUN Rscript -e "pak::pkg_install('rstudio/plumber@main')"
# install other R packages
RUN Rscript -e "pak::pkg_install(c('logger','tictoc', 'fs', 'httr', 'dplyr', 'workflows', 'bundle', 'xgboost'))"
# setup workspace
COPY . /app
WORKDIR /app
ENTRYPOINT ["Rscript"]
CMD ["app.R"]
EXPOSE 8000Image následne vytvoríme pomocou príkazu:
docker compose build --no-cache api
Následne kontajner umiestnime na server, ktorý sme si vybrali na nasadenie. V našom prípade je to Google Cloud Platform.
Zavolanie API
Na úvod malé upozornenie: Prvé zavolanie môže trvať dlhšie kvôli cold startu.
URL
API je teraz možné zavolať rôznymi spôsobmi. Typickým je napr. zavolanie priamo z prehliadača cez URL:
https://appartments-model-api-api-217473566915.europe-central2.run.app/predict?name_nsi=Senec&condition=Novostavba&area=72&provision=0&certificate=A&type=3_i_b
V tomto prípade sme zavolali endpoint /predict s parametrami name_nsi, condition, area, provision, certificate a type. Tieto parametre sú definované v našom API a sú potrebné na vykonanie predikcie. Odpoveď bude vo formáte JSON, ktorý obsahuje predikovanú cenu bytu:
{
"predicted_price": 203338.1719
}Programové volanie
Druhým, praktickejším, spôsobom je zavolanie API programovo. Môžete použitiť akýkoľvek jazyk, ktorý podporuje HTTP požiadavky. V nasledujúcom príklade ostaneme v R, ale rovnako to bude fungovať aj v Pythone, Jave, C#, PHP a iných jazykoch. Pre účely demonštrácie použijeme primárne knižnice httr2 a shiny. V Quarto súbore môžeme vytvoriť jednoduchú aplikáciu, ktorá nám umožní zadať parametre a získať predikciu ceny bytu.
Načítanie knižníc a dát
library(bslib)
library(bsicons)
library(httr2)
library(dplyr)
library(shiny)
library(shinybusy)
mun_list <- readRDS("data/municipalities.RDS")
cond_list <- readRDS("data/conditions.RDS")
cert_list <- readRDS("data/certificates.RDS")
type_list <- data.frame(
type = c("1-izbový byt", "2-izbový byt", "3-izbový byt", "4-izbový byt", "5-izbový byt"),
id = c("1_i_b", "2_i_b", "3_i_b", "4_i_b", "5_i_b")
)
prov_list <- data.frame(
prov = c("Áno", "Nie"),
id = c(1, 0)
)UI
layout_sidebar(
height = 700,
width = 700,
sidebar = sidebar(
shiny::selectizeInput(
'select_mun',
'Obec',
choices = mun_list$Obec,
selected = mun_list$Obec[1],
multiple = FALSE
),
shiny::selectizeInput(
'select_cond',
'Stav',
choices = cond_list$Stav,
selected = cond_list$Stav[1],
multiple = FALSE
),
shiny::selectizeInput(
'select_cert',
'Certifikát',
choices = cert_list$Certifikát,
selected = cert_list$Certifikát[1],
multiple = FALSE
),
shiny::selectizeInput(
'select_type',
'Typ bytu',
choices = type_list$type,
selected = type_list$type[1],
multiple = FALSE
),
shiny::selectizeInput(
'select_prov',
'Provízia v cene',
choices = prov_list$prov,
selected = prov_list$prov[1],
multiple = FALSE
),
shiny::sliderInput(
'area',
'Rozloha (m2)',
min = 50,
max = 150,
value = 70
),
shiny::actionButton(
"submit",
"Zavolať API",
icon = shiny::icon("calculator"),
class = "btn-primary"
)
),
use_busy_spinner(spin = "flower",
color = "primary"),
value_box(
title = "Predikovaná cena",
value = textOutput("prediction"),
showcase = bs_icon("house"),
max_height = "100px",
width_full_screen = "4oopx"
)
)Server
# URL API
api_url <- "https://appartments-model-api-api-217473566915.europe-central2.run.app/predict"
# Reaktívna funkcia pre získanie predikcie z API
predicted_price <- reactiveVal(NULL)
observeEvent(input$submit, {
show_spinner()
req(input$select_mun, input$select_cond, input$area, input$select_cert, input$select_type, input$select_prov)
type_valid <- type_list |>
filter(type == input$select_type) |>
pull(id)
provision_numeric <- prov_list |>
filter(prov == input$select_prov) |>
pull(id)
response <- request(api_url) |>
req_url_query(
name_nsi = input$select_mun,
condition = input$select_cond,
area = input$area,
provision = provision_numeric,
certificate = input$select_cert,
type = type_valid
) |>
req_perform() |>
resp_body_json()
hide_spinner()
predicted_price(response$predicted_price[1])
})
output$prediction <- renderText({
req(predicted_price())
paste0(format(round(predicted_price(), 0), big.mark = " ", decimal.mark = ","),
" €")
})Aplikácia je jednoduchá a umožňuje zadať parametre pre predikciu ceny bytu. Po kliknutí na tlačidlo “Zavolať API” sa zavolá API a zobrazí sa predikovaná cena bytu. Vyskúšať si ju môžete na Shinyapps.io.
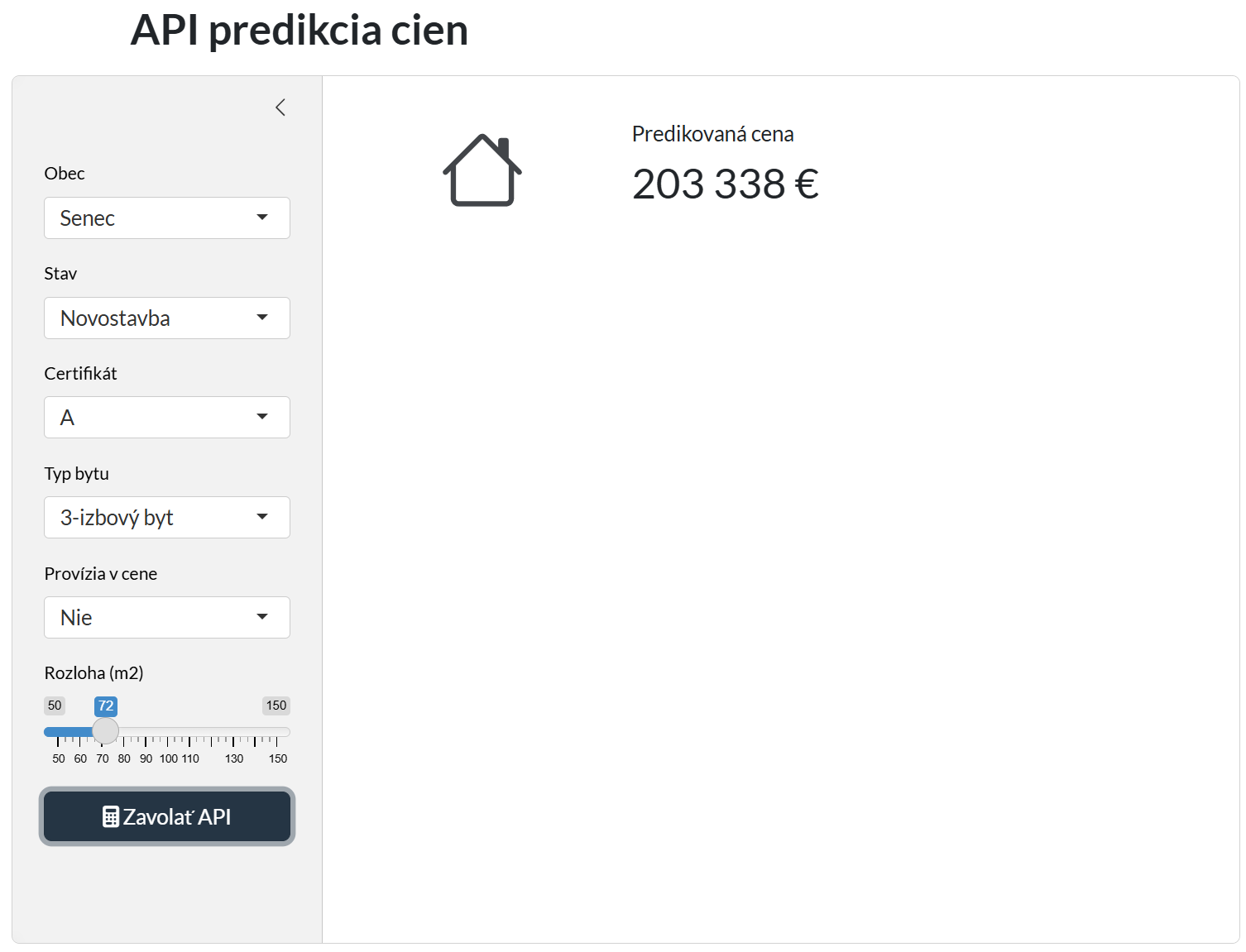
Vytvorenie takejto mini aplikácie je veľmi jednoduché a rýchle (otázka minút).
Záver
R má svoje silné stránky, ktoré nie je potrebné obmedzovať len na analýzu. S využitím vhodných knižníc ako je Plumber (prípadne Plumber2, ktorý je v aktívnom vývoji a dá sa inštalovať z GitHubu) môžeme jednoducho a efektívne sprístupniť transormačné pipeline-y, ML modely, generátory reportov a mnoho ďalších dátových produktov do vnútra firmy alebo aj širšej verejnosti. Druhý benefit môže byť oddelenie business logiky od aplikácie, čo môže byť užitočné pri vývoji a údržbe aplikácií.
Či už si zvolíte na sprístupmenie API URL alebo väčšiu aplikáciu, Plumber vám ponúka flexibilitu a jednoduchosť.
V produkcii sa teda netreba báť použiť R. Mýty o pomalosti tohto jazyka vychádzajú skôr z nevhodných programátorských praktík užívateľov (ktorých báza, je tvorená akademikmi a odborníkmi v oblasti life sciences bez znalostí z oblasti programovania) ako z nedostatkov samotného jazyka.
You might also like
-
Ako zrýchliť XGBoost v R: Benchmark trénovania modelu na CPU vs. GPU https://cleandata.sk/wp-content/themes/engic/images/empty/thumbnail.jpg 150 150 cleandata https://secure.gravatar.com/avatar/ee96a699da7fa28e99fc6752011335df?s=96&d=mm&r=g

-
EDA časových radov: Ako odhaliť vzory skryté v čase https://cleandata.sk/wp-content/themes/engic/images/empty/thumbnail.jpg 150 150 cleandata https://secure.gravatar.com/avatar/ee96a699da7fa28e99fc6752011335df?s=96&d=mm&r=g
-
susR: Zjednodušenie práce s dátami Štatistického úradu SR v R https://cleandata.sk/wp-content/themes/engic/images/empty/thumbnail.jpg 150 150 cleandata https://secure.gravatar.com/avatar/ee96a699da7fa28e99fc6752011335df?s=96&d=mm&r=g

Leave a Reply