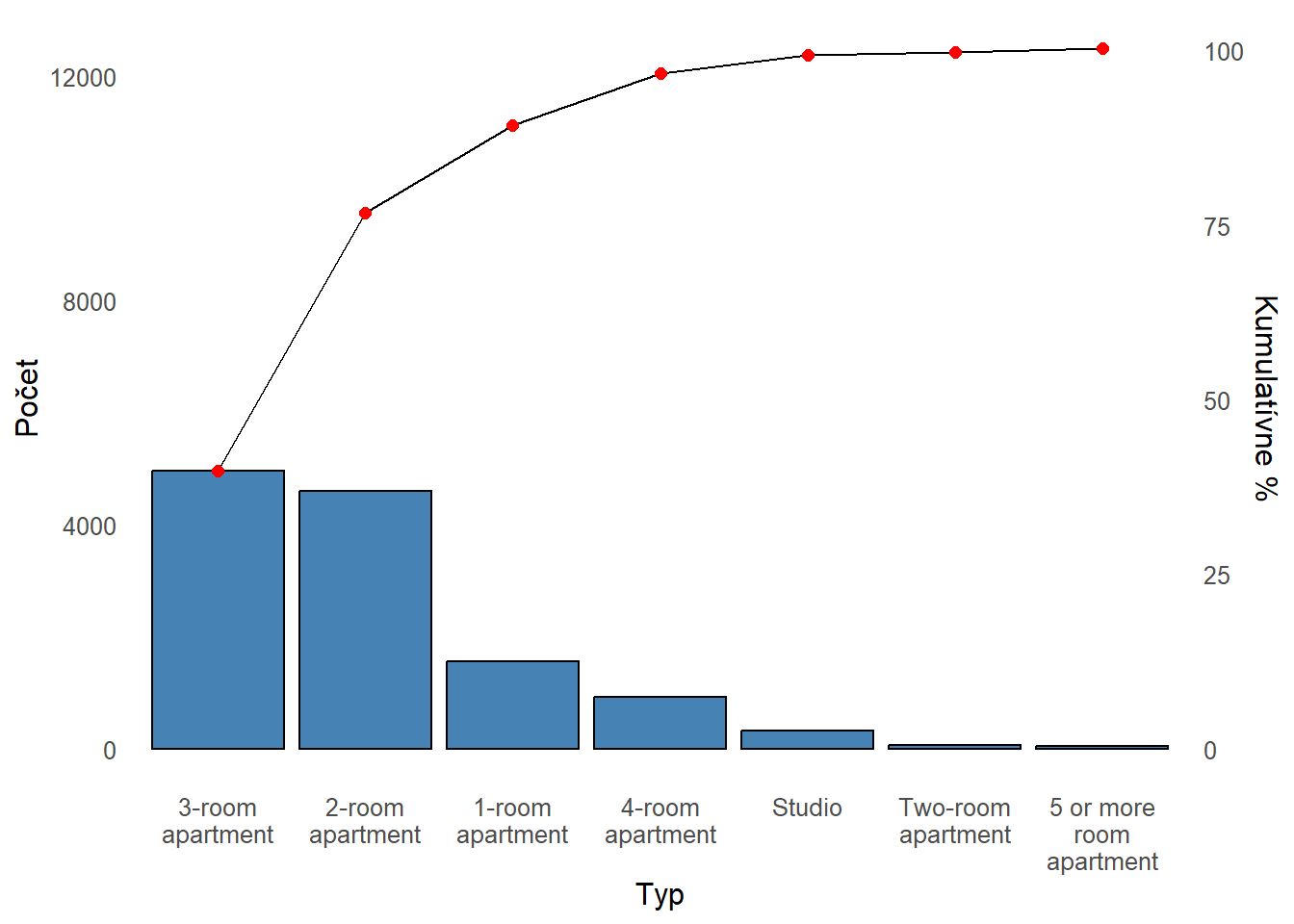
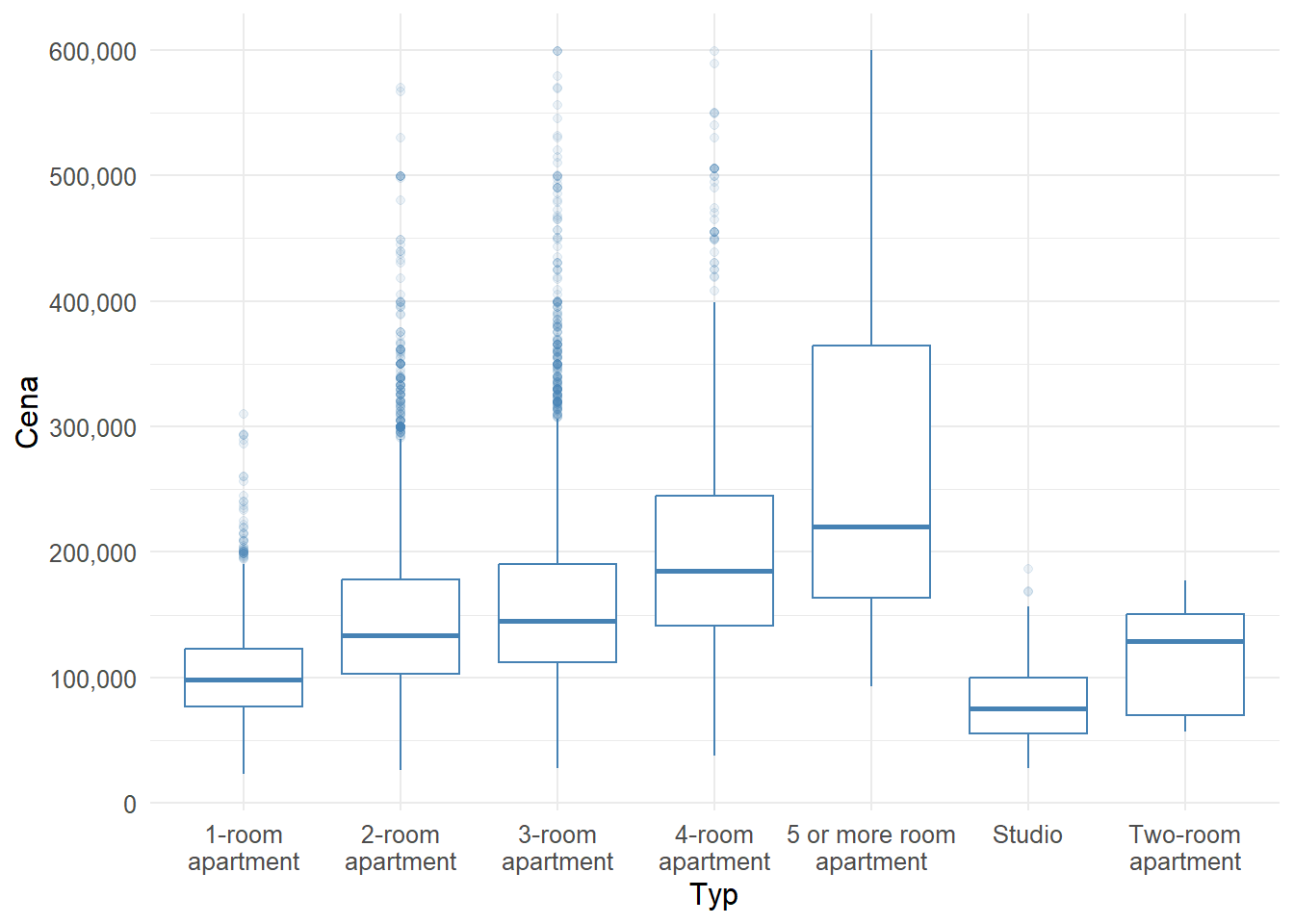
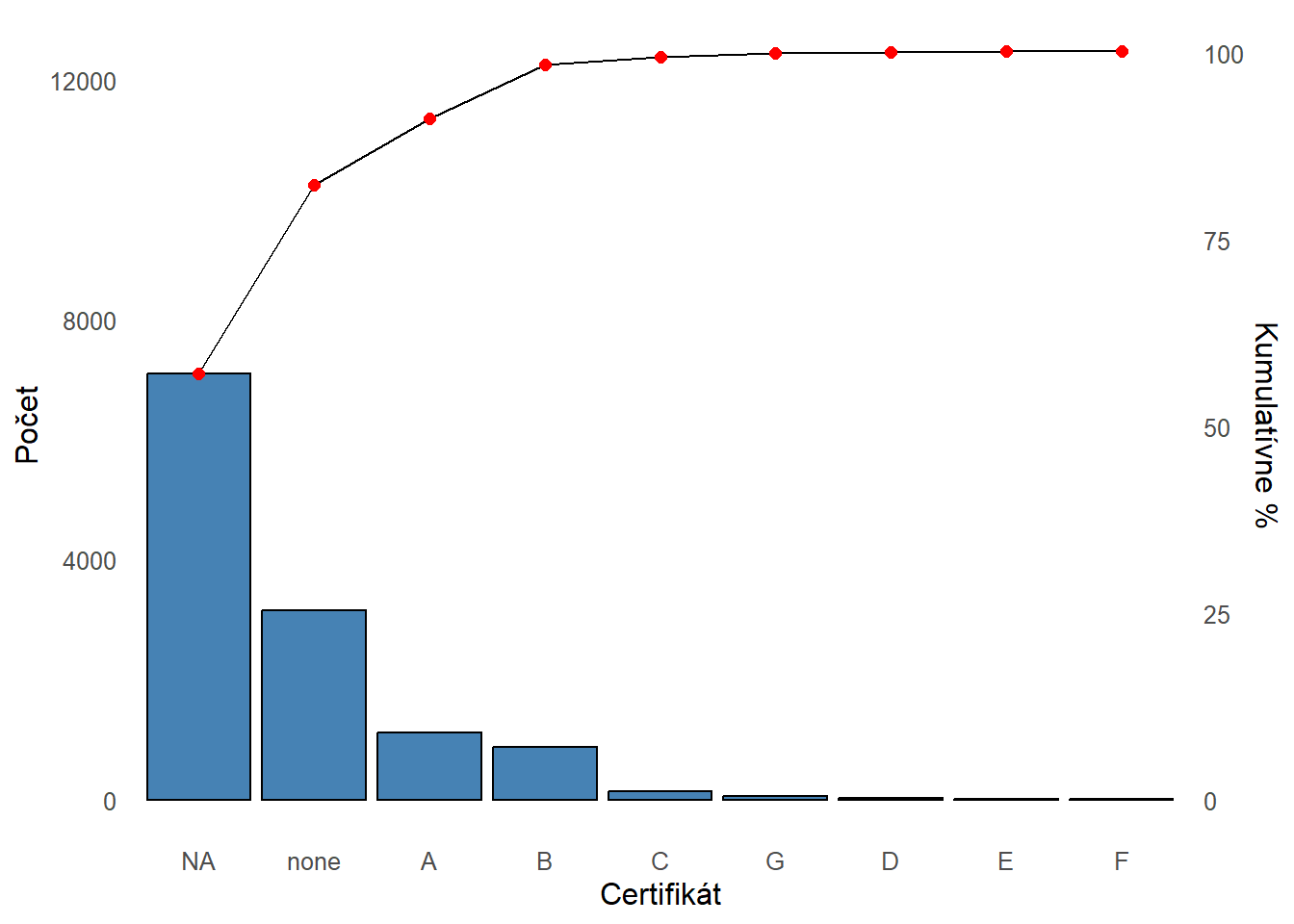
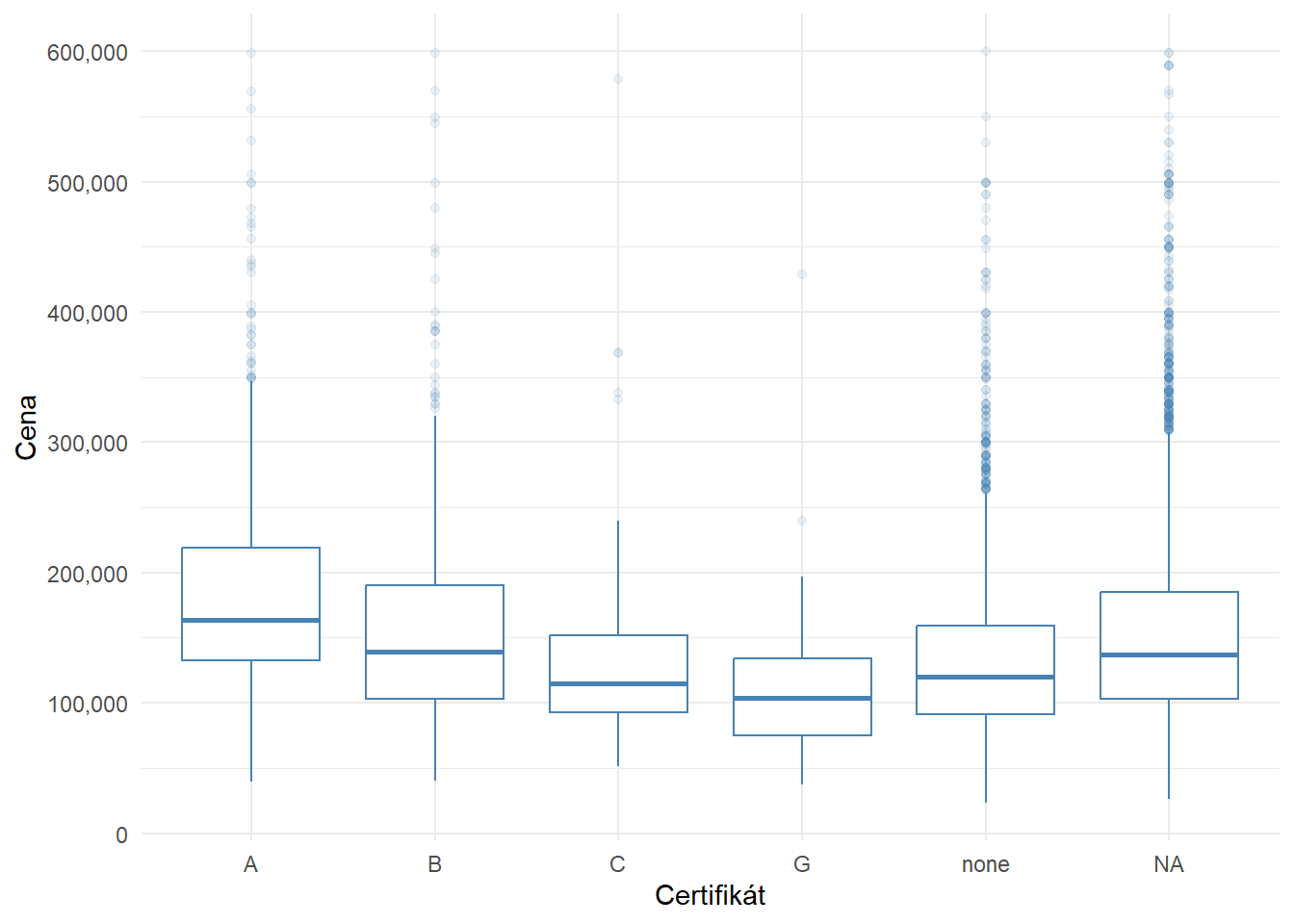
Efektívne vizualizácie dát pomocou Gestalt princípov
Gestalt princípy zohrávajú kľúčovú úlohu pri tvorbe zrozumiteľných vizualizácií dát. Tento článok skúma, ako tieto princípy pomáhajú organizovať vizuálne prvky tak, aby efektívne komunikovali informácie a minimalizovali kognitívne zaťaženie užívateľa. Prostredníctvom príkladov v R je ukázané, ako správna aplikácia týchto princípov zvyšuje čitateľnosť a prehľadnosť grafov, čo vedie k lepšiemu porozumeniu prezentovaných dát.
Úvod
Gestalt princípy sú základné pravidlá, ktoré vysvetľujú, ako ľudia vnímajú vizuálne elementy ako celok. Svoj pôvod majú v Gestalt (celostnej) psychológii zo začiatku 20. storočia. Základnú myšlienku vyslovil Kurt Koffka: “The whole is something else than the sum of its parts”, čiže celok je niečo iné, ako suma jeho častí. Tieto princípy sú kľúčové pri tvorbe efektívnych a zrozumiteľných vizualizácií dát (čiže takých, ktoré jasne komunikujú, čo je “signál” v našich dátach). Dobrá vizualizácia je vytváraná ako celok. Jej jednotlivé časti meníme takým spôsobom, aby tento celok jasne komunikoval hlavnú myšlienku a nevytváral zbytočne veľké kognitívne zaťaženie užívateľa. V tomto článku sa pozrieme na 6 všeobecne rozoznávaných Gestalt princípov a ukážeme si, ako ich aplikovať pri vizualizácii dát pomocou R.
Princíp blízkosti (proximity)
Objekty, ktoré sú blízko pri sebe máme tendenciu považovať za časť jednej skupiny.

V BI tento princíp môžeme využiť napr.v dizajne reportov. Aj tak jednoduchý element ako medzera medzi vizuálmi dokáže jednoducho sprehľadniť celý report. Oblasť filtrov, KPI kariet, grafov alebo tabuliek nepotrebujú špeciálne orámovanie. Stačí ich rozumne vzdialiť od seba a efekt je rovnaký a navyše čistejší.
Princíp podobnosti (similarity)
Objekty, ktoré maju podobný tvar, farbu alebo veľkosť sú vnímané ako jedna skupina. Tento princíp využíva napr. PowerBI v základnom dizajne tabuliek. V nich sa farba pozadia riadkov striedavo mení medzi bielou a sivou, čo pomáha čítať riadky, najmä ak je tabuľka široká. Typicky tento princíp využívame pri porovnávaní rôznych kategórií, ktorým priraďujeme rôznu farbu.

Princíp oblasti/ohraničenia (enclosure)
Objekty, ktoré sú spoločne uzavreté, považujeme za súčasť jednej skupiny. Uzavretie nemusí byť výrazné, aby sme dokázali využiť tento princíp. Vďaka tomuto princípu môžeme upriamiť pozornosť na tú časť dát, ktorú považujeme za najdôležitejšiu.
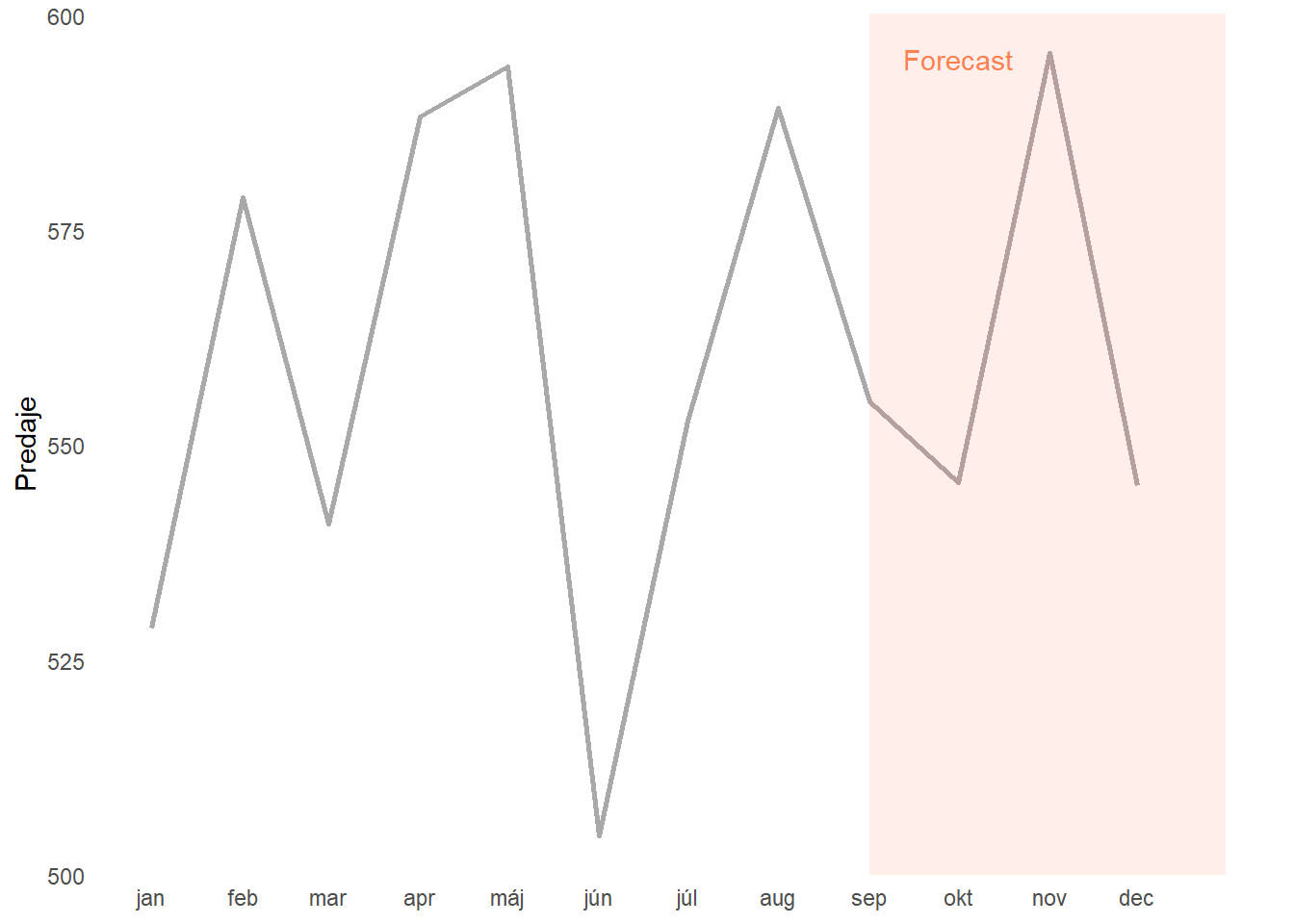
Princíp uzavretosti (closure)
Tento princíp asi najlepšie vystihuje citát z úvodu: “The whole is something else than the sum of its parts”. Na obrázku nižšie ako prvé zbadáme kruh. Nerozmýšlame nad ním ako množstvom čiar, ale považujeme ho za celok. V našich mysliach máme množstvo takýchto konštruktov. Rovnako, ak nejaká časť celku chýba, dokážeme si ju podvedome doplniť.
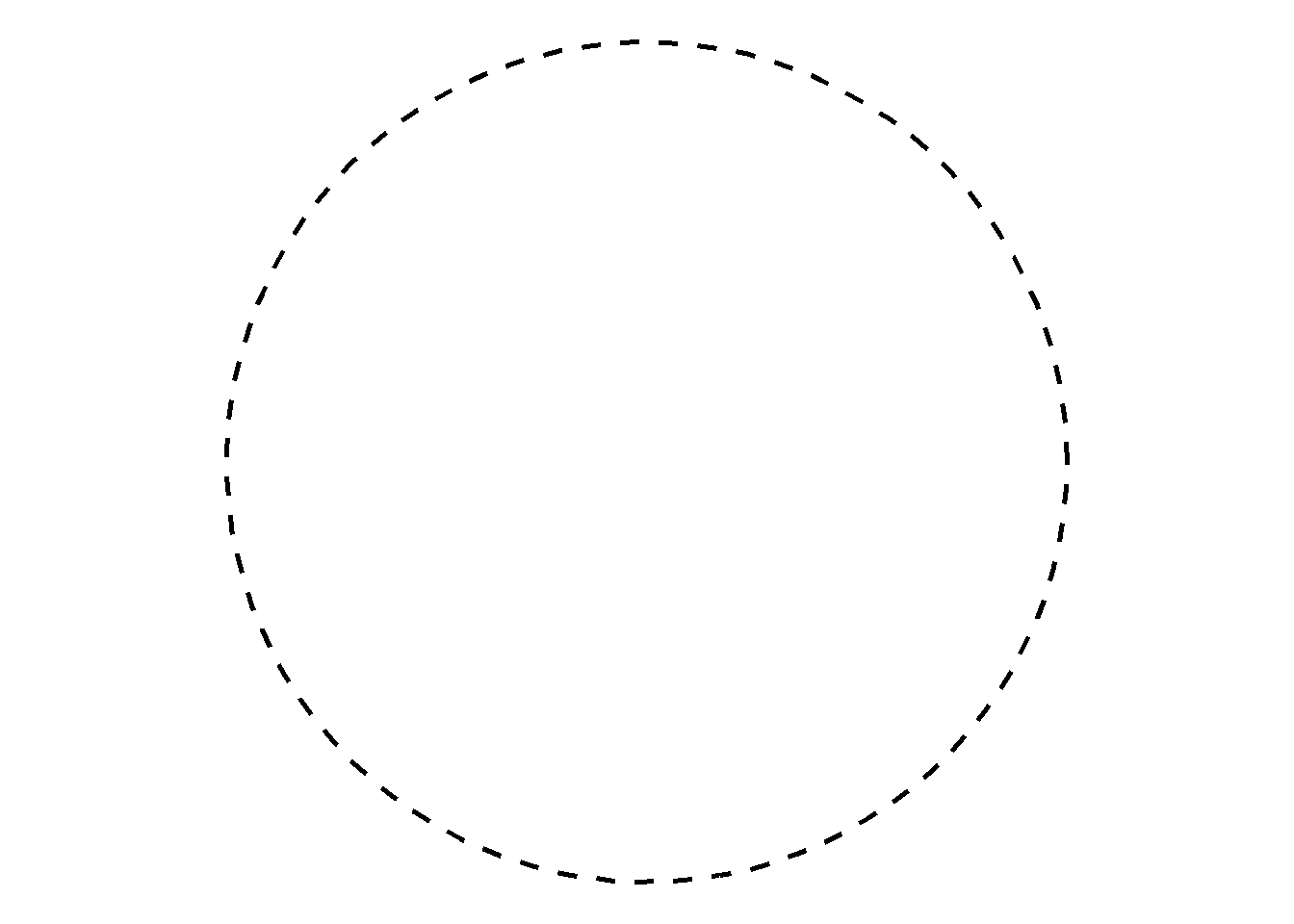
V praxi vieme tento princíp použiť pri odstraňovaní zbytočných elementov ako orámovanie, farebné pozadie, vodiace čiary atď. Napriek tomu užívateľ bez problému rozozná, o aký typ vizualizácie sa jedná a informácia v nej môže vďaka čistejsiemu dizajnu vyniknúť viac.
Princíp plynulosti (continuity)
Princíp plynulosti hovorí, že ľudia majú tendenciu sledovať hladké kontinuálne vzory. Toto môžeme využiť pri čiarových grafoch, kde plynulé línie pomáhajú sledovať trendy v dátach. Druhou možnou aplikáciou je zoraďovanie podľa hodnoty. Pri doplnkových elementoch ako nadpis, podnadpis, značenie osí atď. by mali mať rovnaké zarovnanie a odsadenie.
Princíp prepojenia (connection)
Posledný princíp hovorí, že objekty, ktoré sú prepojené, vnímame ako jednu entitu. Toto môžeme aplikovať pri vizualizáciách, kde sú dátové body prepojené čiarami alebo inými vizuálnymi prvkami ako čiarové a pásové grafy, “slope” grafy a iné. Prepojenie vyvoláva väčšinou silnejšiu asociáciu ako tvar alebo farba, ale menšiu ako ohraničenie.
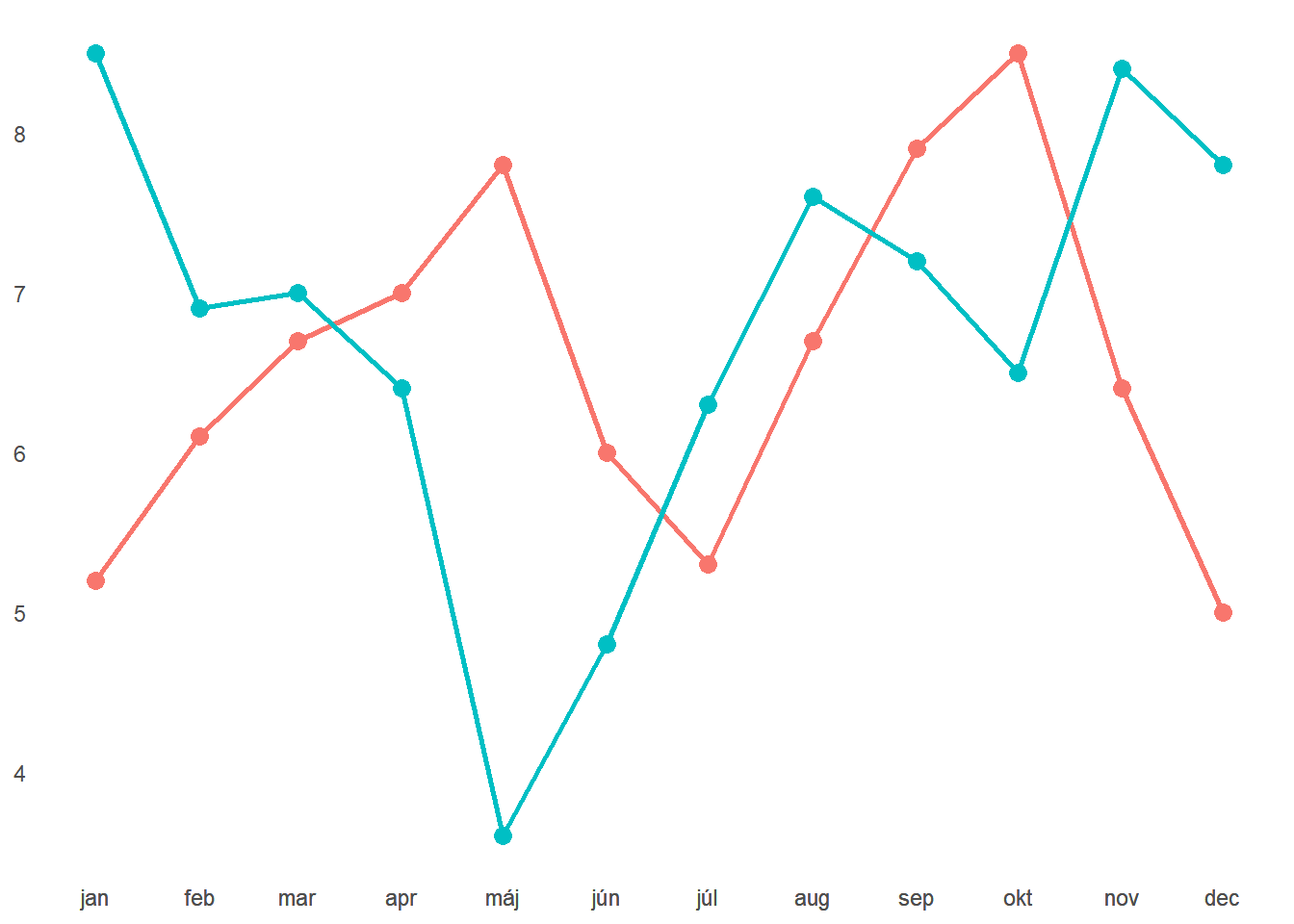
Praktický príklad
Pozrime sa na príklad aplikácie rôznych princípov a ako menia naše vnímanie.
Začneme s bodovým grafom.
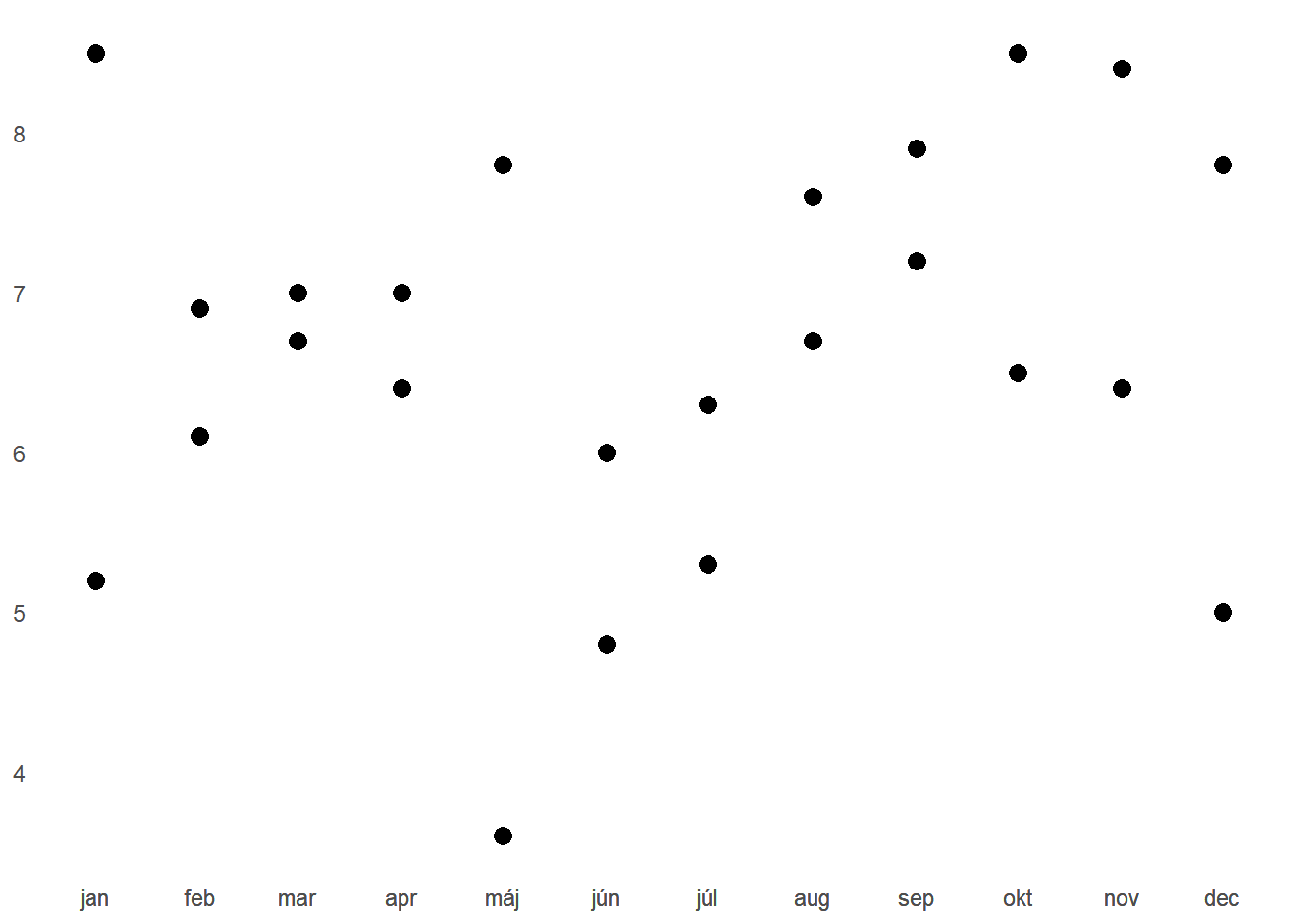
Pri prvom pohľade sa zrejme jedná o zobrazenie dvoch skupín, keďže v každom mesiaci máme dve hodnoty. Nevieme ale určiť, kam jednotlivé body patria, či existuje nejaký signál v dátach. Skôr to vyzerá na náhodný zhluk bodov.
Pri aplikácii princípu podobnosti (tvar a farba) sa čitateľnosť aj množstvo informácií, ktoré vieme vyčítať, výrazne zvyšuje.
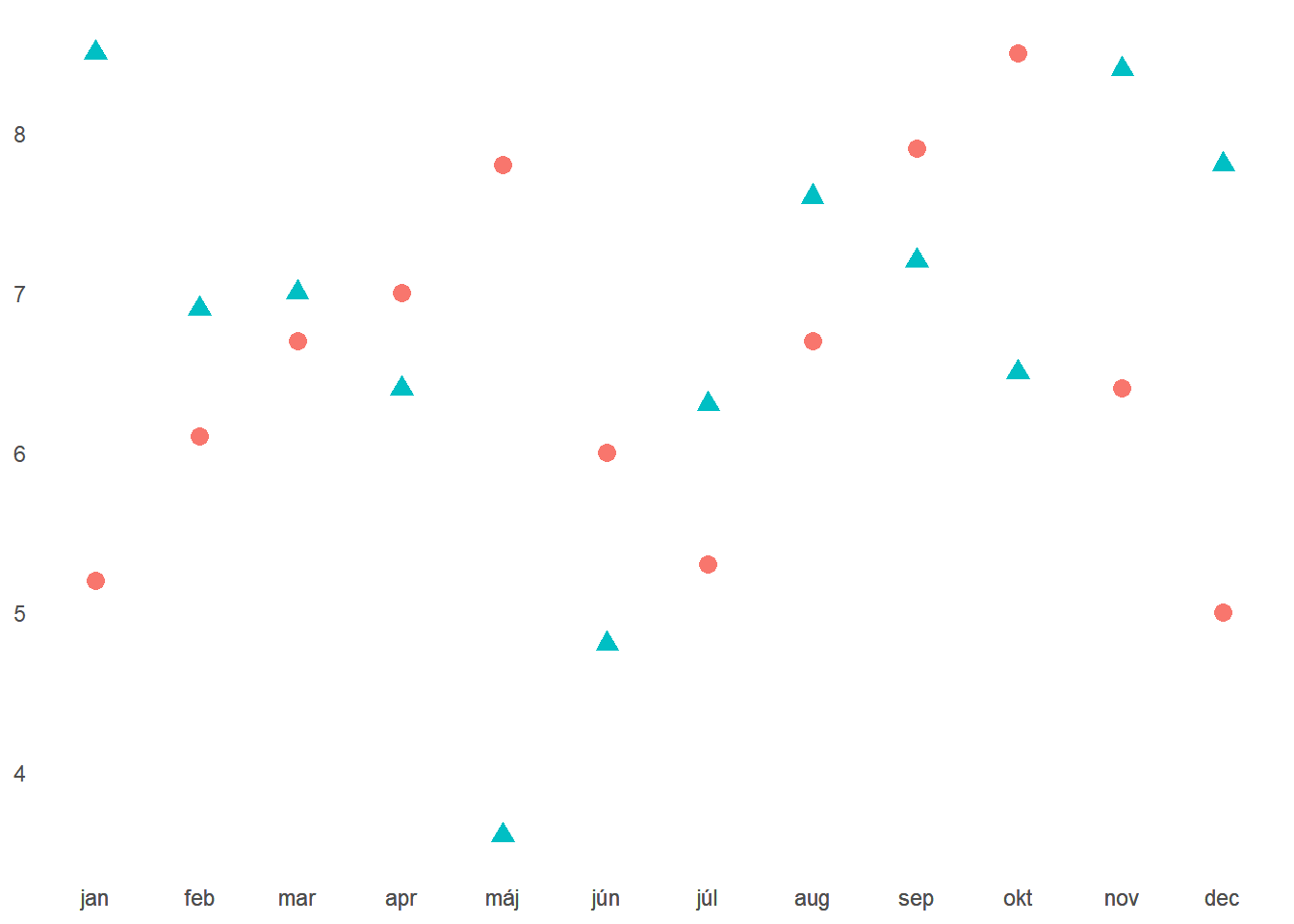
Jedna skupina dosahuje vyššie hodnoty na začiatku aj konci roka, mesiace apríl až jún ma však slabé. Druhá skupina má naopak mesiace apríl až jún silnejšie, v máji je pritom rozdiel najväčší z celého roka. Napriem tomuto zlepšeniu sa graf stále nečíta veľmi dobre. Body príliš skáču a je ťažké udržat na nich pozornosť.
Skúsme teda ešte aplikovať princíp prepojenia.
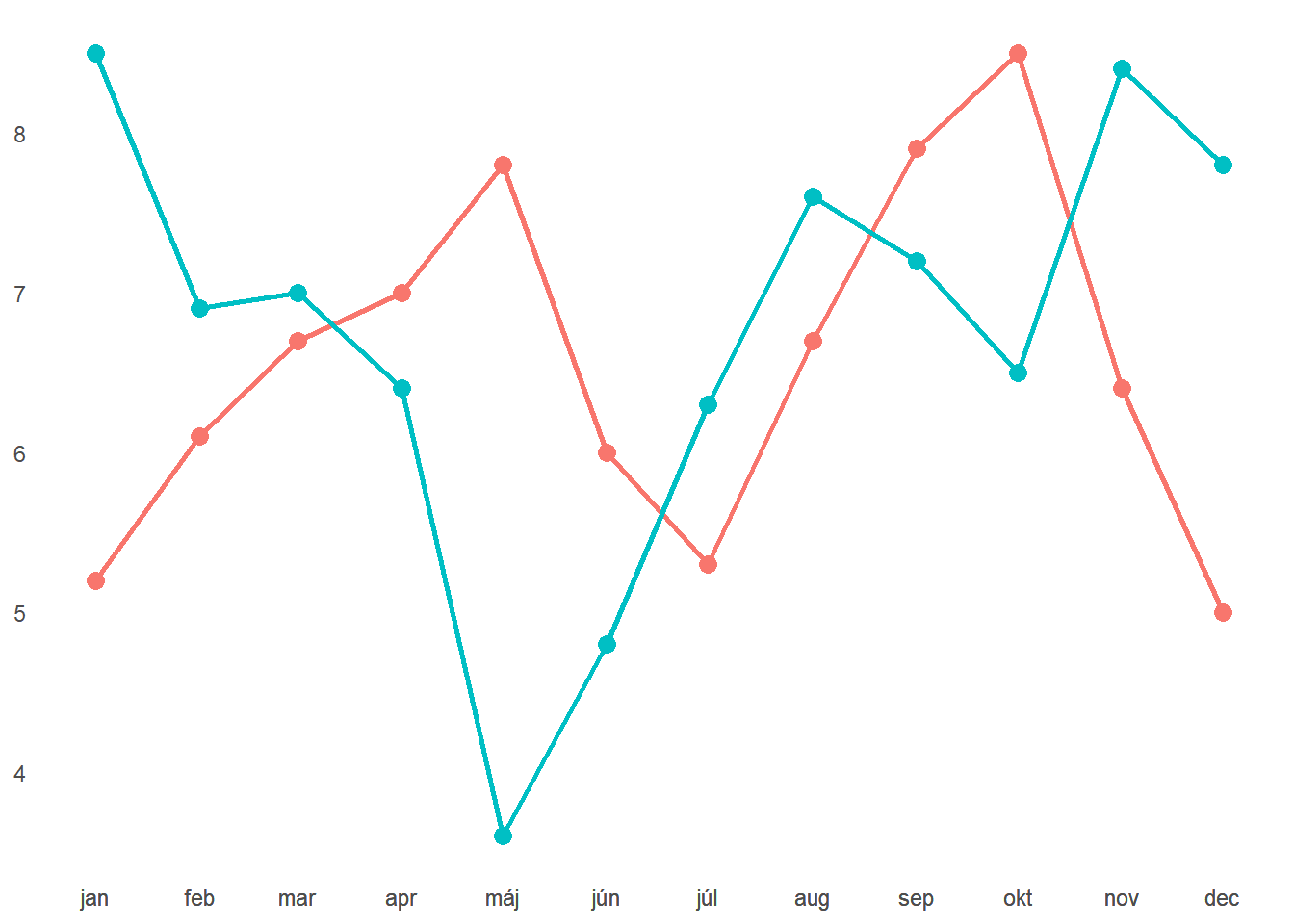
Čitateľnosť je oveľa ľahšia. Vďaka prepojeniu bodov nemusíme vynakladať veľa úsilia na sledovanie a porovnanie trendu. Zmena v tomto kroku sa mi zdá byť ešte výraznejšia než predchádzajúca. Pri prvom grafe by väčšina používateľov strávila len minimum času a rýchlo by ho preskočila, pretože informácie neboli na prvý pohľad zaujímavé. Druhý graf už poskytol potrebný kontext – jasne vidíme rozdiely medzi dvomi radmi, ktoré by sme nemali prehliadať. Avšak, porozumenie tomuto grafu vyžaduje veľa sústredenia a môže byť únavné. Pridanie prepojenia výrazne zjednodušilo graf a umožnilo nám rýchlejšie a ľahšie pochopiť viac informácií. Mimochodom, všimli ste si, že sme odstránili jeden komponent podobnosti? Rovnaký tvar nežnížil vnímanie rozdielov. Mohli sme ho ponechať, ale všeobecne by som odporučil odstrániť každý element, ktorý sám o sebe nepridáva hodnotu.
Ako posledný aplikujeme princíp ohraničenia.
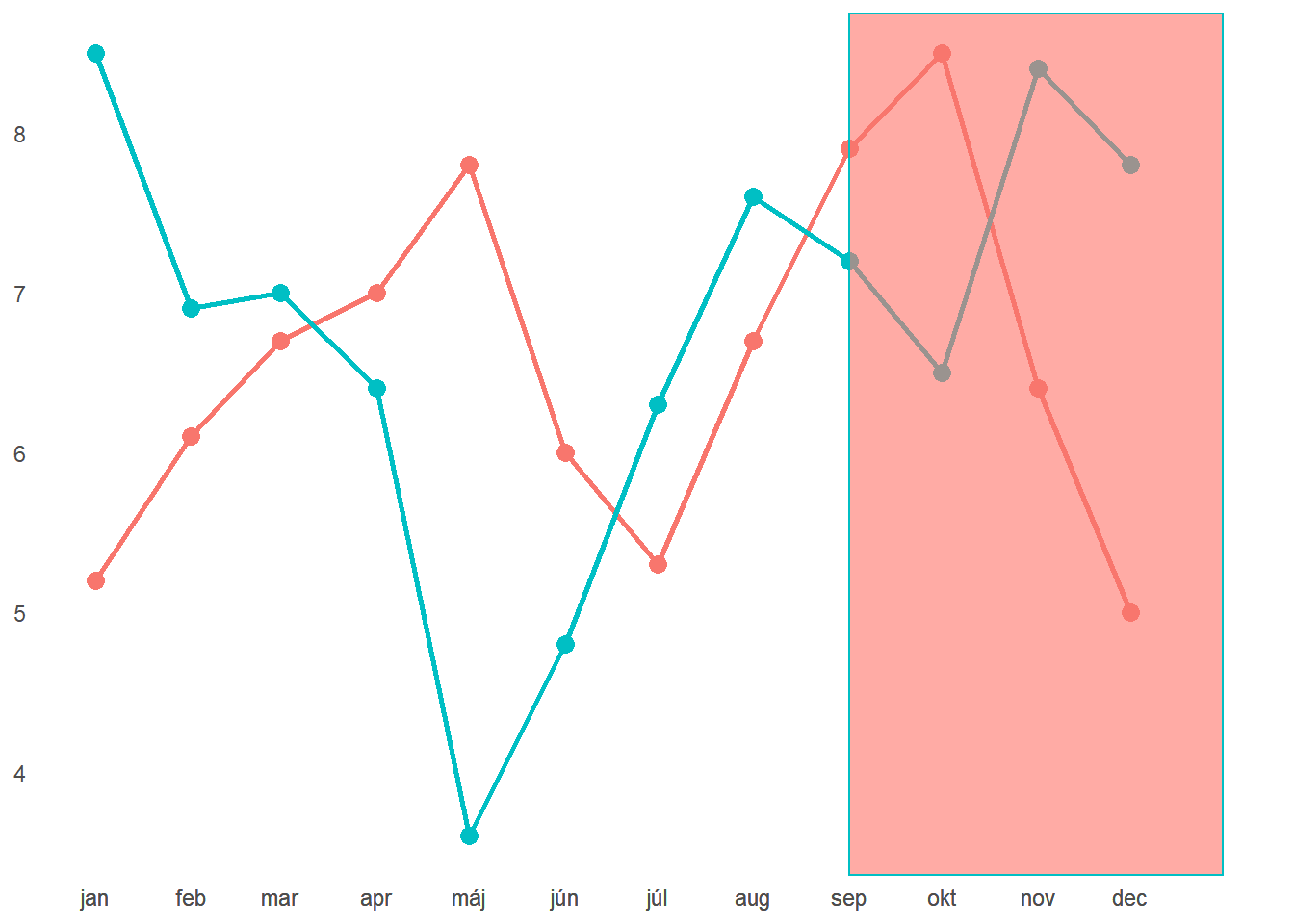
Keď sa na graf pozrieme teraz, zrejme nám ako prvá padne do oka výrazná červená oblasť, ktorá je v jasnom kontraste so zvyškom grafu. Typicky sa môže jednať o predpokladaný vývoj do konca roka a neohraničená oblasť bude doterajší reálny vývoj. Následne sa presúvame k vnímaniu informácií z predchádzajúcich krokov ako rozdiel v trendoch dvoch skupín.
Záver
Gestalt princípy sú mocným nástrojom pri navrhovaní vizualizácií dát, ktoré sú nielen esteticky príjemné, ale aj efektívne v komunikácii komplexných informácií. V tomto blogovom príspevku sme si prešli 6 kľúčových princípov blízkosť, podobnosť, ohraničenie, uzavretosť, plynulosť a prepojenie a ukázali sme si, ako ich aplikovať pri tvorbe vizualizácií v jazyku R. Tieto princípy nám pomáhajú usmerňovať pozornosť užívateľa, znižovať kognitívne zaťaženie a zvyšovať zrozumiteľnosť prezentovaných dát.
Pri tvorbe vizualizácií je dôležité mať na pamäti, že každý element by mal byť v návrhu zámerne umiestnený a mal by prispievať k hlavnému cieľu vizualizácie. Zbytočné prvky by mali byť eliminované, aby sa predišlo preťaženiu užívateľa informáciami. Používanie Gestalt princípov vám umožní vytvárať vizualizácie, ktoré sú nielen vizuálne príťažlivé, ale aj funkčné a efektívne v sprostredkovaní informácií.
Ak by ste sa chceli dozvedieť viac o problematike ako vizualizovať a komunikovať dáta, odporúčam knihu od Cole Nussbaumer Knaflic – Storytelling with Data, ktorá odkazuje na mnoho ďaľších zdrojov, a tiež súvisiacu stránku https://www.storytellingwithdata.com/.