Forecasting so strojovým učením
V tomto blogu sa zameriavam na moje prvé skúsenosti s účasťou v forecast súťaži, kde som sa rozhodol otestovať nové metódy. Namiesto tradičných štatistických prístupov som sa sústredil na použitie modelov strojového učenia (ML). Hlavným cieľom bolo preskúmať, ako môžu moderné ML metódy zlepšiť presnosť predikcií v porovnaní s bežne používanými štatistickými technikami.
Moje prvé skúsenosti a lekcie z forecast súťaže od rohlik.cz
Nedávno som sa po prvýkrát zúčastnil forecastovacej súťaže na Kaggle. Organizovala ju spoločnosť Rohlik.cz. Aj keď môj výsledok bol pre mňa osobne sklamaním, keďže som skončil v 27. percentile, súťaž mi priniesla množstvo cenných skúseností a ponaučení, ktoré stoja za zmienku.
Prvé skúšanie ML na forecasting
Táto súťaž bola mojou prvou príležitosťou vyskúšať forecasting pomocou strojového učenia. Doteraz som využíval najmä tradičné štatistické metódy ako ARIMA a ETS. Tentokrát som sa rozhodol pre strojové učenie z nasledujúcich dôvodov:
- Cieľom bolo forecastovať denné objednávky. S tradičnými metódami mám dobrú skúsenosť, pokiaľ sa jedná napr. o mesačnú agregáciu a mám dostupné historické dáta za dostatočne dlhé obdobie (niekoľko rokov). V tomto prípade sme mali dostupné údaje za relatívne krátke historické obdobie.
- Strojové učenie bolo víťaznou stratégiou v mnohých predchádzajúcich súťažiach ako napr. M4, M5 alebo v súťaži organizovanej spoločnosťou Intermarché. Preto považujem za dôležité mať praktickú skúsenosť aj s týmto spôsobom forecastovania.
- Už dlhšie som sa chystal vyskúšať knižnicu modeltime a ďalšie, k nej doplnkové knižnice.
- Praktická skúsenosť s novou metódou mi pomôže aj v pracovnej sfére.
Priebeh a výsledok
Na súťaži som pracoval vo voľnom čase, čo znamenalo, že som musel prioritizovať, čomu sa chcem venovať.
Základ by ideálne bol rozsiahly a kvalitný feature engineering. Spätne musím povedať, že som mu mal venovať viac času. Rozdiely v konečnom hodnotení boli relatívne malé a verím, že práve lepšie features by ma vedeli posunúť na vyššiu priečku. Avšak hlavným cieľom bolo vyskúšať nové knižnice a metódy, takže som venoval až neprimerane veľa času (ak by sa jednalo o reálny projekt) ich implementácii.
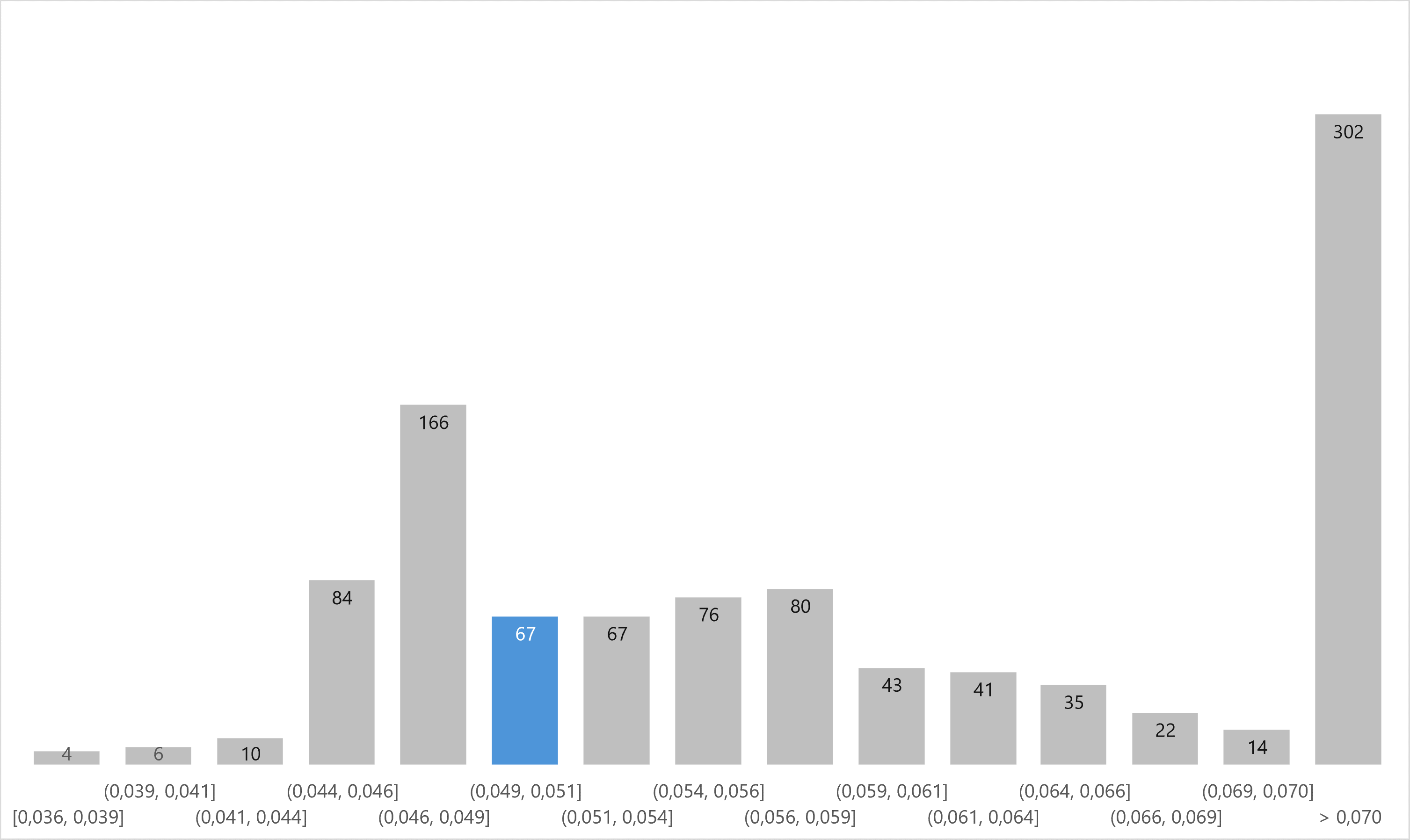
Hodnotená metrika bola MAPE. Nie je to ideálna metrika, keďže jednotlivé sklady, pre ktoré sa robili forecasty, mali veľmi rozdielny objem objednávok (od dolných tisícov po vyse 11 tisíc) a teda 10% odchýlka v jednom sklade mohla byť 200 objednávok a 4% odchýlka v inom 400 objednávok. Moja výsledná hodnota MAPE bola 0,0489, pričom v priebežnom public leaderboarde bola 0.0396 a v cross-validácii 0,0331. Napriek tomuto zhoršeniu sa mi priečka posunula len o 8 miest dole.
Problém so súťažami na Kaggle je, že mnoho súťažiacich skopíruje dobré uverejnené riešenia iných a nahrajú výsledky. Na grafe nižšie je efekt pekne viditeľný v intervale 4,6% až 4,9% a bol často kritizovaný v diskusiách. Nie je nič zlé na inšpirovaní sa u iných, avšak skopírovanie celého kódu s kozmetickými úpravami je neetické. V grafe som zvýraznil interval, v ktorom sa nachádzalo moje riešenie. Objektívne však menej ako 5% odchýlku na denných predajoch pre 7 skladov na nasledujúcich 60 dní považujem za dobrý výsledok. Graf tiež dobre ilustruje ako blízko boli riešenia pri sebe. Šírka intervalov je 0,25 percenta.
Testovanie rôznych prístupov
Zvolil som dva rôzne prístupy, ktoré som chcel otestovať.
Prvý bol tradičnejší workflow – feature engineering, zadefinovanie modelu, tuning hyperparametrov s cross-validáciou a následný testing na testovacej sade dát. Použil som tri rôzne algoritmy: XGBoost, LightGBM a Random Forest. Každý z týchto modelov má svoje vlastné silné stránky, no výsledky ukázali, že v priemere najlepší bol LightGBM, mierne horší XGBoost a po nich s väčším prepadom v presnosti Random Forest. Keďže sa však výsledky jednotlivých modelov mierne líšili podľa skladu, pre ktorý bol forecast robený, rozhodol som sa použiť ensemble prístup s meta learner modelom (použitý algoritmus bol GLMnet). Tento model použil výsledky z troch algoritmov plus dve premenné – sklad a deň v týždni. Je celkom bežné, že aj obyčajné spriemerovanie nezávislých forecastov zlepší výslednú presnosť.
Druhý prístup bol rekurzívny ML model. Ten obsahuje všetky kroky z predchádzajúceho workflowu, ale pridáva sa funkcia, ktorá dopočítava niektoré hodnoty z predchádzajúcich dní. Napr. predaje v predchádzajúci deň, 7 dní dozadu, dva týždne dozadu atď. Tento proces je pomalší, lebo vyžaduje, aby sa robil forecast po jednom dni, ten sa následne “doplní” do dátového setu a vstupuje do nasledujúceho forecastu už ako prediktor. Jedná sa teda o iteratívny proces. Keďže tento model postupne predikoval hodnoty pre jednotlivé časové obdobia na základe predchádzajúcich predikcií, jeho presnosť závisí od presnosti predchádzajúcich predikcií, čo prináša určité riziká.
Jedným špecifikom forecastov časových radov je, že cross-validácia (CV) by mala rešpektovať kontinuitu času. Time series cross-validation môže mať niekoľko podôb, napr. sliding alebo expanding window, testovacie dáta môžu priamo nadväzovať na trénovacie alebo môžeme aplikovať lag. Spoločná myšlienka za nimi však je, že pri trénovaní modelov pre predpovedanie časových radov by v prípade klasických metód ako k-fold CV dochádzalo k tzv. data leakage (trénovanie modelu na dátach z budúcnosti a teda na informáciách, ktoré by model nemal mať). Vačšina riešení, ktoré sú zverejnené sa však tejto téme nevenuje a rovno uvádza hodnoty hyperpametrov, ktoré boli aplikované.
Dôležitosť feature engineeringu
Jedným z najzaujímavejších zistení bolo, že viacero z top riešení v súťaži používalo len jeden model – LightGBM. Najlepšie riešenie nemá príliš dobrú dokumentáciu, avšak toto riešenie skončilo na 2. mieste a potvrdilo, že niekedy menej je viac. Tento úspech ukazuje, že najdôležitejším krokom je správny feature engineering. V niektorých prípadoch je lepšie investovať viac času do správnej prípravy dát, než do komplikovaných modelov, ktoré sú v podstate „blackboxom“. V tejto súťaži sa navyše nedalo príliš spoliehať na priebežné výsledky v public leaderboarde, keďže validačný set dát mal len 31 % z už tak krátkeho forecastovaného obdobia. Namiesto toho bolo lepšie dôverovať výsledkom vlastnej cross-validácie.
Záver
Aj keď som nedosiahol výsledky v aké som dúfal (byť aspoň v top 20 percent), súťaž mi dala možnosť vyskúšať si nové techniky, zdokonaliť svoje schopnosti v oblasti strojového učenia a získať cenné skúsenosti. Ak sa zúčastňujete podobných súťaží, nezabudnite, že aj keď váš model nedosiahne top skóre, stále sa môžete veľa naučiť a získať inšpiráciu z vyššie umiestnených riešení.
You might also like
-
Ako zrýchliť XGBoost v R: Benchmark trénovania modelu na CPU vs. GPU https://cleandata.sk/wp-content/themes/engic/images/empty/thumbnail.jpg 150 150 cleandata https://secure.gravatar.com/avatar/8c8d8a5e6252e444fa20e8dcf3ae56e750328f39393987d1aa94a8911b0632b8?s=96&d=mm&r=g

-
Machine learning v jazyku R – Odhad cien bytov https://cleandata.sk/wp-content/themes/engic/images/empty/thumbnail.jpg 150 150 cleandata https://secure.gravatar.com/avatar/8c8d8a5e6252e444fa20e8dcf3ae56e750328f39393987d1aa94a8911b0632b8?s=96&d=mm&r=g

Leave a Reply